




行情火爆 注意观察强势股 是否爆量滞涨 与 市场量能持续性
市场已经完成了一圈轮动 医药 科技 券商 地产 免税 银行
后面几天大盘股应该会平淡一些 个股唱戏 不太应该指数一下打到3200 那基本上全都跑路了 后面几天 应该会分化
止盈了天箭
这里 可能是牛市的起点 也可能是 短期行情的尾端 没有人知道
享受过程 不追高就行。
观察上证指数 已经意义不大 现在完全是各版块的独立行情 看创业板50 沪深300 和中证500 加个股的独立量能与K线
沪深300 毫无回调欲望 5日线都没摸
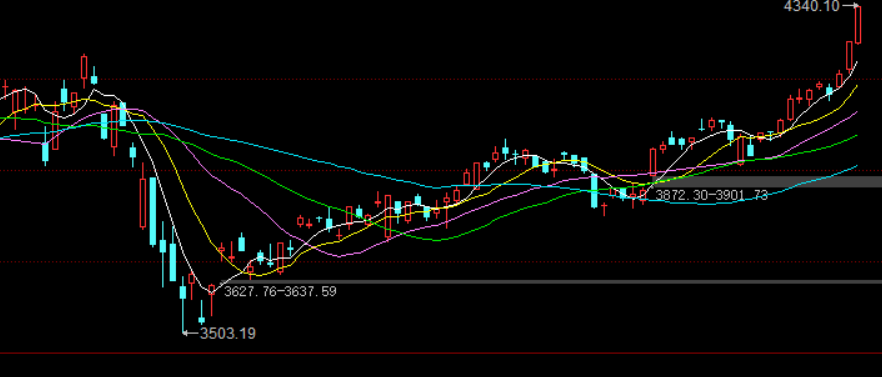
中证500也是突破前高 上上周 画过 我计划在黄线 未突破的话 减仓 今天强势突破 注意观察接下来的几天 是继续上涨 还是回踩确认 还是 直接拐头向下 。
最健康的走势应该是 回踩确认再继续 强势拉上去的话 获利盘太多
目前5979 下一阻力位6100
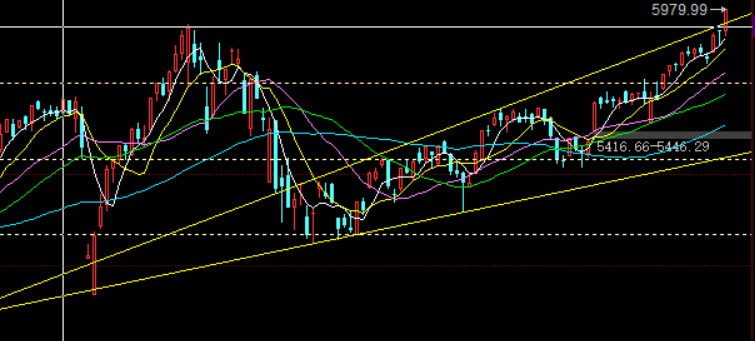
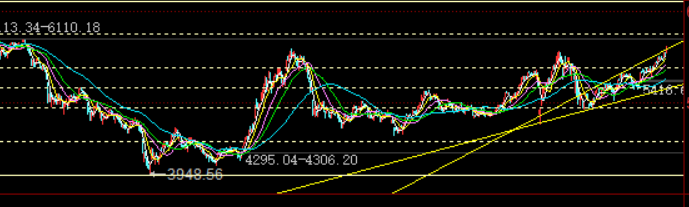
这两天大批股神又冒出来了 大家基本都赚钱 我就不发持仓股了 只要不买医药 不追热点 挺好赚钱的 5G 和miniled 果链 我比较看好
K-means算法原理
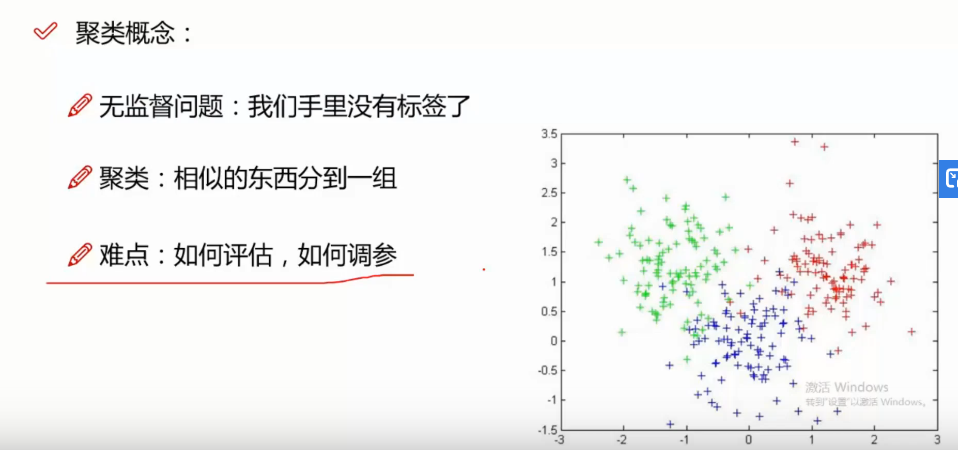


如果用数据表达式表示,假设簇划分为
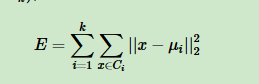
其中
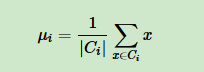
如果我们想直接求上式的最小值并不容易,采用迭代方法。
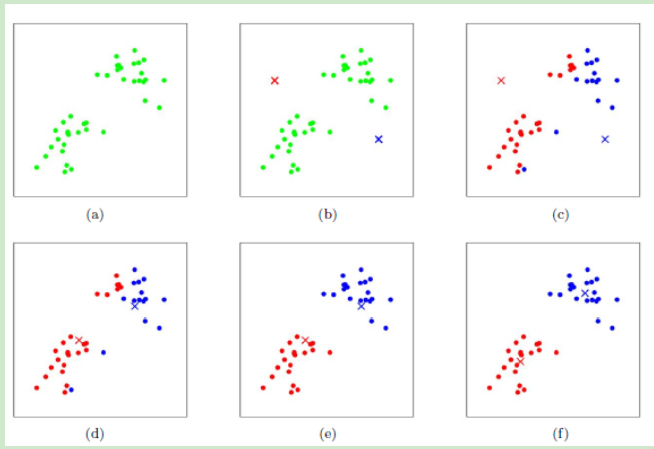
1)对于K-Means算法,首先要注意的是k值的选择,一般来说,我们会根据对数据的先验经验选择一个合适的k值,如果没有什么先验知识,则可以通过交叉验证选择一个合适的k值。
2)在确定了k的个数后,我们需要选择k个初始化的质心,就像上图b中的随机质心。由于我们是启发式方法,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的k个质心,最好这些质心不能太近。
总结下K-Means算法流程。打了好几遍 公式乱码直接贴图了

随机选择K个中心点
把每个数据点分配到离它最近的中心点;
重新计算每类中的点到该类中心点距离的平均值
分配每个数据到它最近的中心点;
重复步骤2和3,直到所有的观测值不再被分配或是达到最大的迭代次数(R把10次作为默认迭代次数)。
KNN算法原理详解:
二.KNN算法介绍
KNN的全称是K Nearest Neighbors,意思是K个最近的邻居,从这个名字我们就能看出一些KNN算法的蛛丝马迹了。K个最近邻居,毫无疑问,K的取值肯定是至关重要的。那么最近的邻居又是怎么回事呢?其实啊,KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。听起来有点绕,还是看看图吧。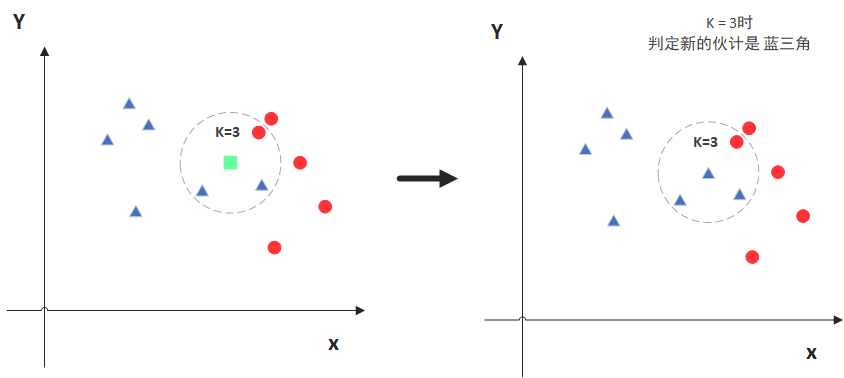
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
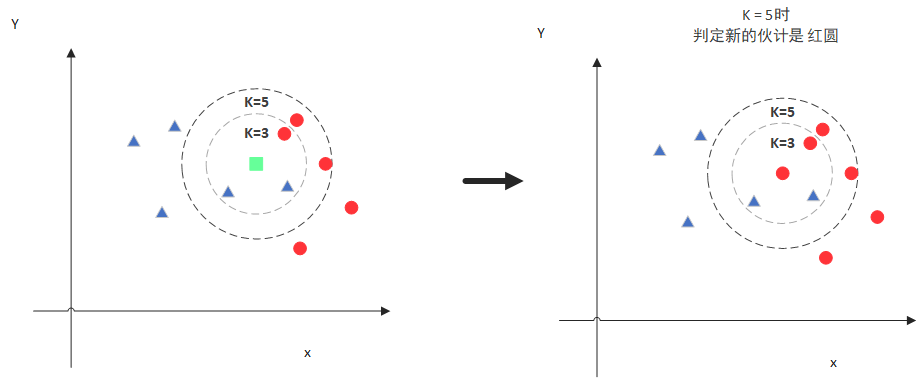
但是,当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。
明白了大概原理后,我们就来说一说细节的东西吧,主要有两个,K值的选取和点距离的计算。
2.1距离计算
要度量空间中点距离的话,有好几种度量方式,比如常见的曼哈顿距离计算,欧式距离计算等等。不过通常KNN算法中使用的是欧式距离,这里只是简单说一下,拿二维平面为例,,二维空间两个点的欧式距离计算公式如下:
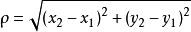
其实就是计算(x1,y1)和(x2,y2)的距离。拓展到多维空间,则公式变成这样:
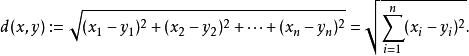
这样我们就明白了如何计算距离,KNN算法最简单粗暴的就是将预测点与所有点距离进行计算,然后保存并排序,选出前面K个值看看哪些类别比较多。但其实也可以通过一些数据结构来辅助,比如最大堆,这里就不多做介绍。
2.2 K值选择
通过上面那张图我们知道K的取值比较重要,那么该如何确定K取多少值好呢?答案是通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值。
通过交叉验证计算方差后你大致会得到下面这样的图: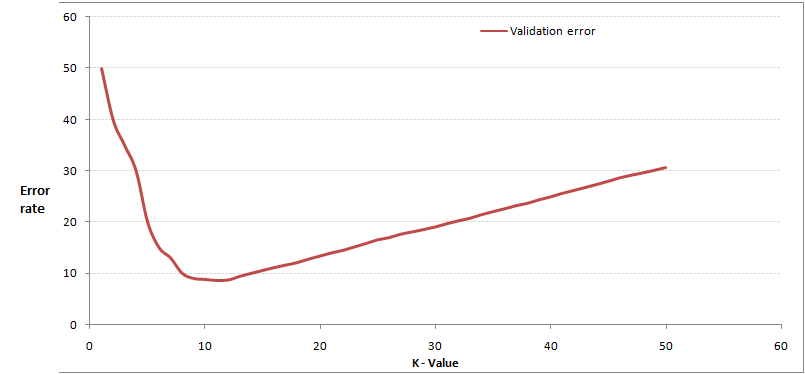
这个图其实很好理解,当你增大k的时候,一般错误率会先降低,因为有周围更多的样本可以借鉴了,分类效果会变好。但注意,和K-means不一样,当K值更大的时候,错误率会更高。这也很好理解,比如说你一共就35个样本,当你K增大到30的时候,KNN基本上就没意义了。
所以选择K点的时候可以选择一个较大的临界K点,当它继续增大或减小的时候,错误率都会上升,比如图中的K=10。
2.3 KNN算法的优势和劣势
了解KNN算法的优势和劣势,可以帮助我们在选择学习算法的时候做出更加明智的决定。那我们就来看看KNN算法都有哪些优势以及其缺陷所在!
KNN算法优点
简单易用,相比其他算法,KNN算是比较简洁明了的算法。即使没有很高的数学基础也能搞清楚它的原理。
模型训练时间快,上面说到KNN算法是惰性的,这里也就不再过多讲述。
预测效果好。
对异常值不敏感
KNN算法缺点
对内存要求较高,因为该算法存储了所有训练数据
预测阶段可能很慢
对不相关的功能和数据规模敏感
