




AlexNet
AlexNet是一个较早应用在ImageNet上的深度网络,其准确度相比传统方法有一个很大的提升。
Alex Krizhevs提出的AlexNet采用了ReLU激活函数,而不像传统神经网络早期所采用的Tanh或Sigmoid激活函数,ReLU数学表达为:



模型参数如下:


经过conv1得到的特征图大小为:([227-11] / 4 + 1 )= 55 。
新的特征图规格为55*55。
更多的参数分析就不写了 都是用上述公式
VGG (16layers):多层(更多)同样大小的卷积层+全连接层
它使用的卷积全部为3x3,Pad=1,步长为1,也就是说,卷积不会改变输出大小,而改变输出大小这件事就交给了2x2,步长为2 的max pool,也就是说每通过一个 max pool,卷积的尺寸都会折半。

VGG与Alexnet相比,具有如下改进几点:
1、去掉了LRN层,作者发现深度网络中LRN的作用并不明显,干脆取消了
2、采用更小的卷积核-3x3,Alexnet中使用了更大的卷积核,比如有7x7 11*11的,因此VGG相对于Alexnet而言,参数量更少
3、池化核变小,VGG中的池化核是2x2,stride为2,Alexnet池化核是3x3,步长为2
还有googlenet我就不介绍了 下面直接介绍Resnet
Resnet原理
在VGG中,卷积网络达到了 16 ,19层,在GoogLeNet中,网络史无前例的达到了22层。网络层数增多一般会伴着下面几个问题
计算资源的消耗
模型容易过拟合
梯度消失/梯度爆炸问题的产生
问题1可以通过GPU集群来解决,对于一个企业资源并不是很大的问题;
问题2的过拟合通过采集海量数据,并配合Dropout正则化等方法也可以有效避免
问题3通过Batch
Normalization也可以避免。貌似我们只要无脑的增加网络的层数,我们就能从此获益,但实验数据给了我们当头一棒。

深层网络 56层 不如20层的模型 优秀
我之前写过一篇详细的resnet的原理
TF2.0使用方式12-梯度消失,爆炸的原因以及残差网络Resnet网络的实现
REST
resnet 使用残差块 解决了 梯度消失(爆炸)的问题

在引入ResNet之前,我们想让该层学习到的参数能够满足H(x)=x,即输入是x,经过该冗余层后,输出仍然为x。但是可以看见,要想学习H(x)=x恒等映射时的这层参数时比较困难的。ResNet想到避免去学习该层恒等映射的参数,使用了如上图的结构,让H(x)=F(x)+x;这里的F(x)我们称作残差项,我们发现,要想让该冗余层能够恒等映射,我们只需要学习F(x)=0。学习F(x)=0比学习h(x)=x要简单,因为一般每层网络中的参数初始化偏向于0,这样在相比于更新该网络层的参数来学习h(x)=x,该冗余层学习F(x)=0的更新参数能够更快收敛。

由于h(x)=F(x)+x,由于链式求导后的结果如图所示,不管括号内右边部分的求导参数有多小,因为左边的1的存在,并且将原来的链式求导中的连乘变成了连加状态(正是 ),都能保证该节点参数更新不会发生梯度消失或梯度爆炸现象。
把 链式求导法则 连乘 变为 1+ 连加状态 所以不会发生梯度消失和梯度爆炸
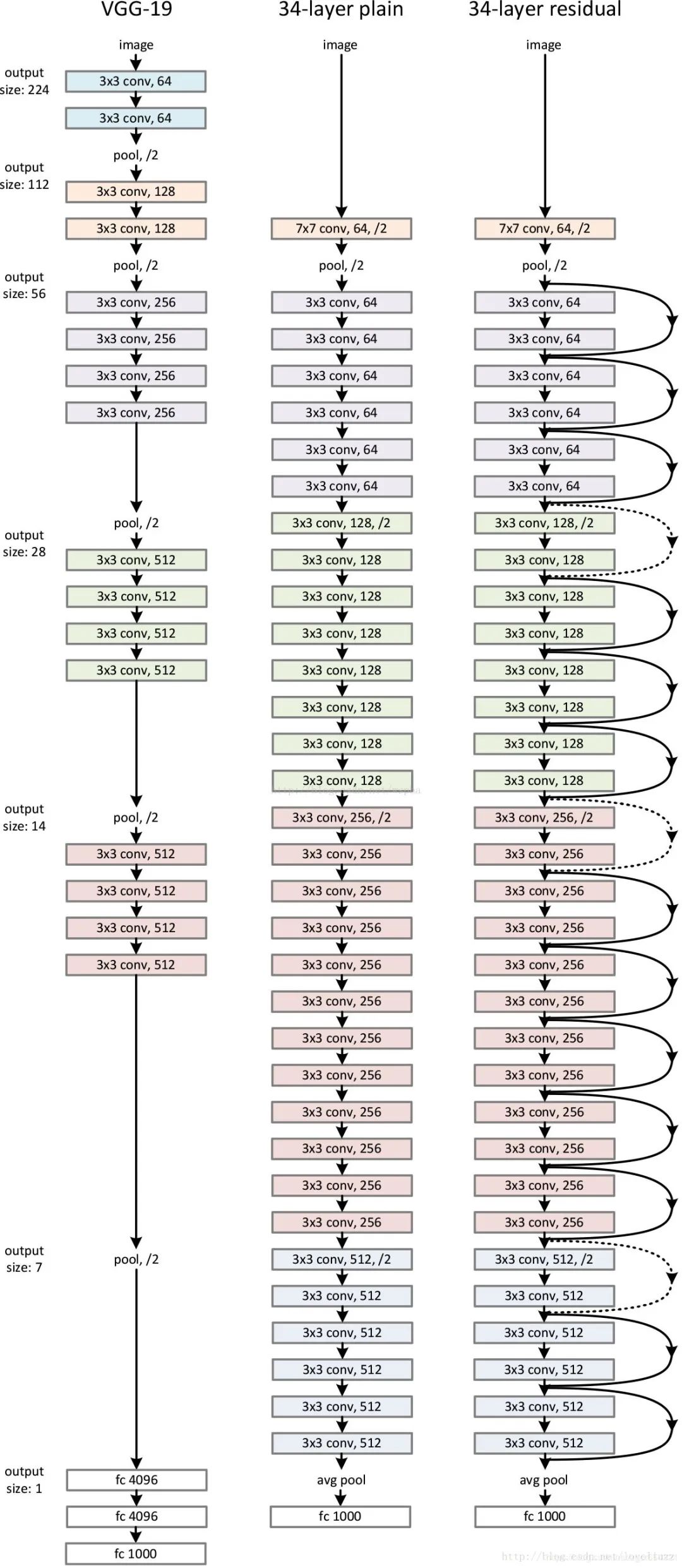
模型如上图
实验结论如下图

