




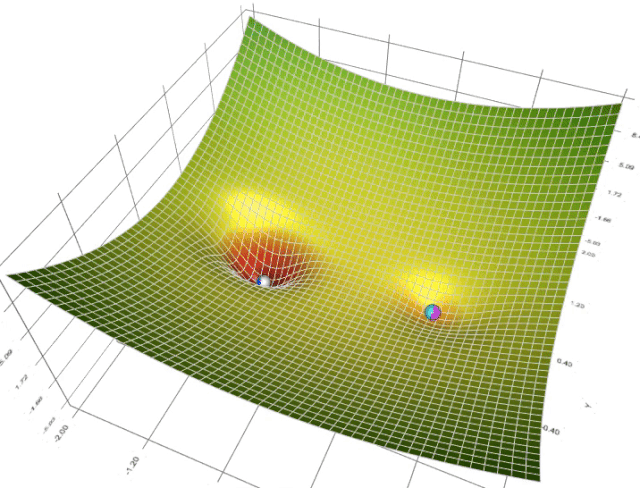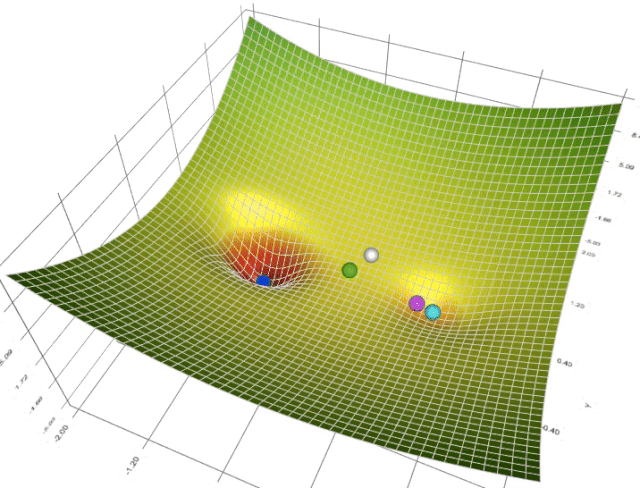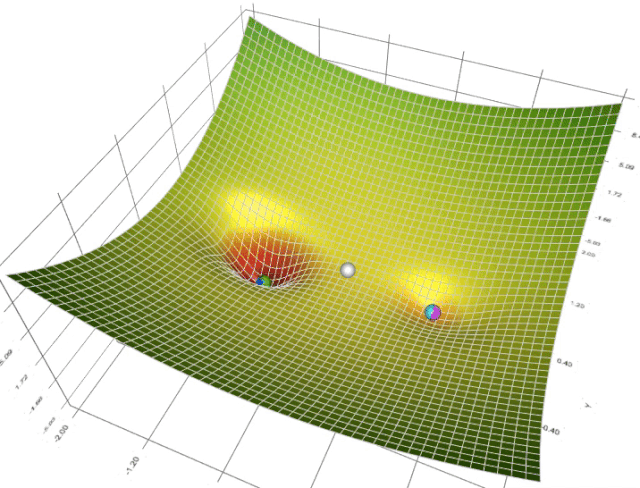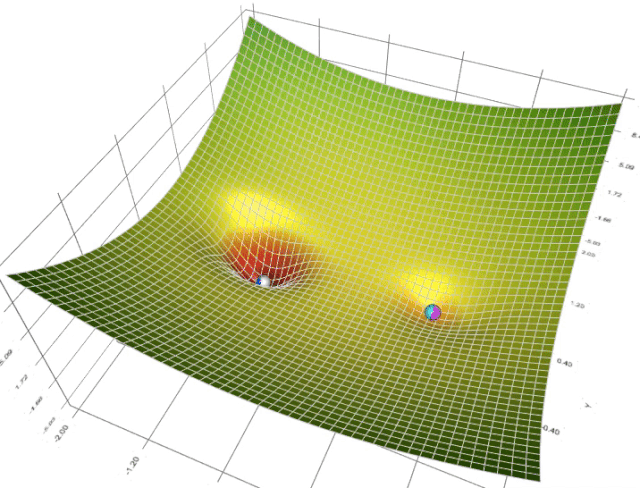
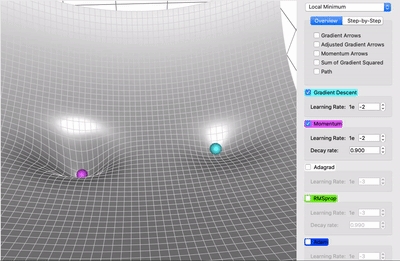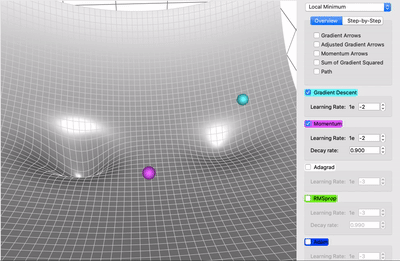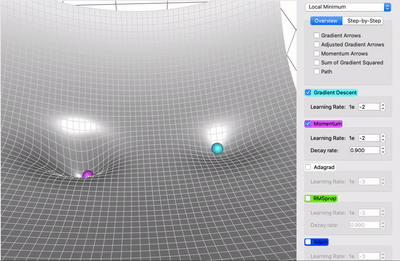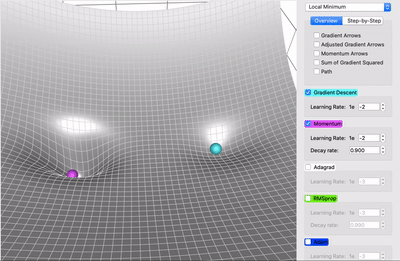
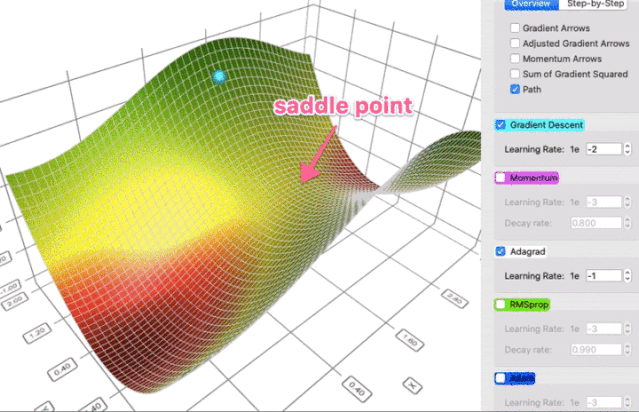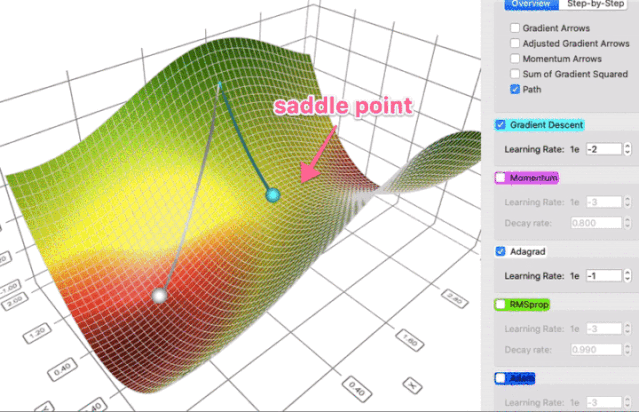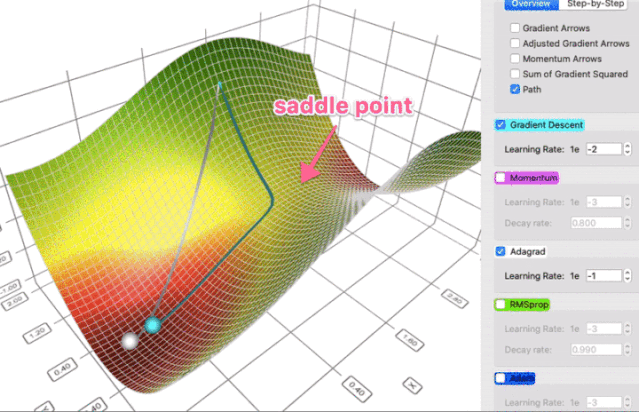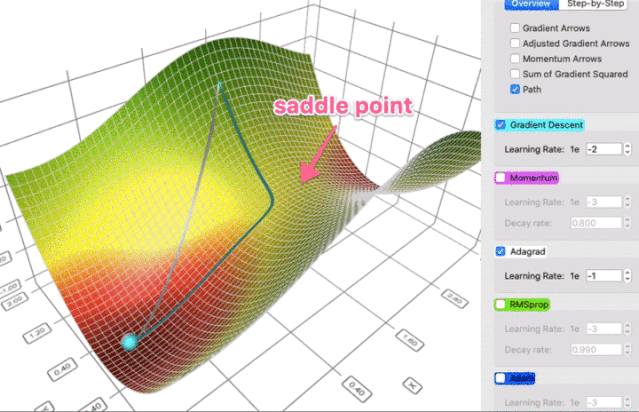
在一个表面上动画演示5个梯度下降法: 梯度下降(青色) ,momentum(洋红色) ,AdaGrad (白色) ,RMSProp (绿色) ,Adam (蓝色)。左坑是全局极小值,右坑是局部极小值
随机梯度下降( Stochastic Gradient Descent,SGD )
随机梯度下降法:

SGD算法在训练过程中很有可能选择被标记错误的标记数据,或者与正常数据差异很大的数据进行训练,那么使用此数据求得梯度就会有很大的偏差,因此SGD在训练过程中会出现很强的随机现象。如何解决呢?
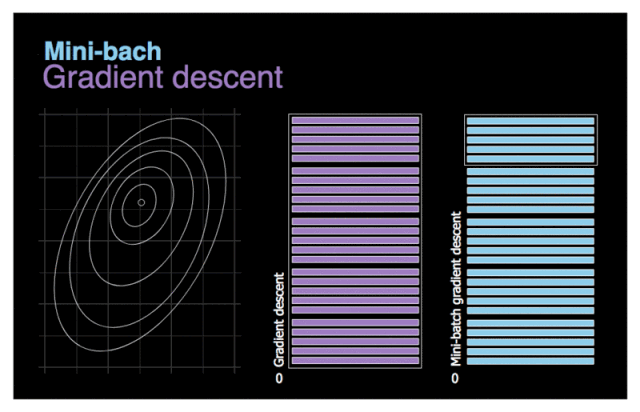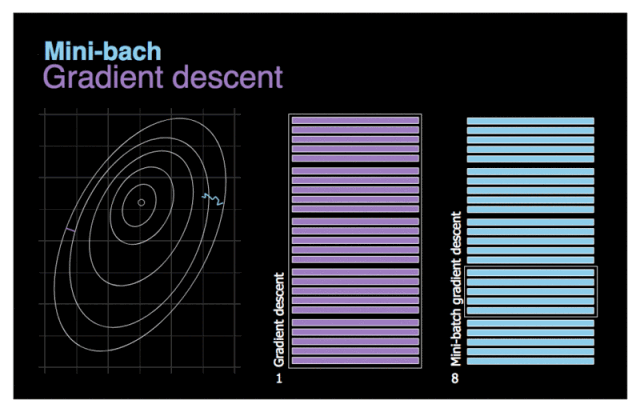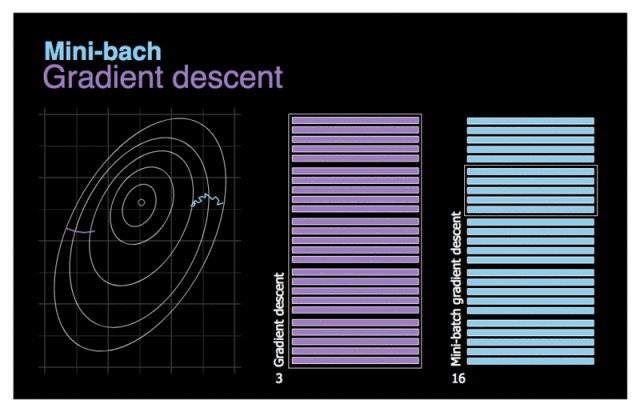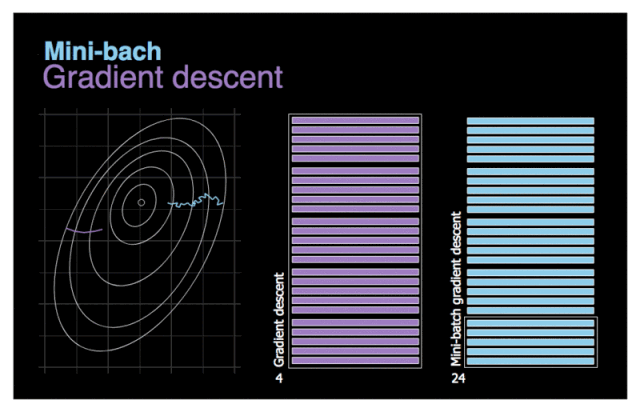
可以多选择几个数据在一起求梯度和,然求均值 minibatch SGD
这样做的好处是即使有某条数据存在严重缺陷,也会因为多条数据的中和而降低其错误程度

momentum 下降法
带有动量的梯度下降算法(简称动量)借鉴了物理学的思想
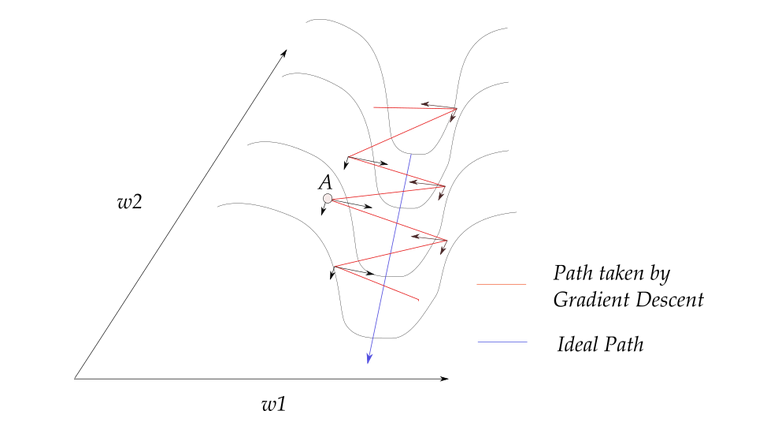
梯度大多数发生更新在Z字形方向上,我们将每次更新分解为W1和W2方向上的两个分量。如果我们分别累加这些梯度的两个分量,那么W1方向上的分量将互相抵消,而W2方向上的分量得到了加强.
积累了W2方向上的分量,抵消了W1方向上的分量,从而帮助我们更快地通往最小值。从这个意义上说,动量法也有助于抑制振荡
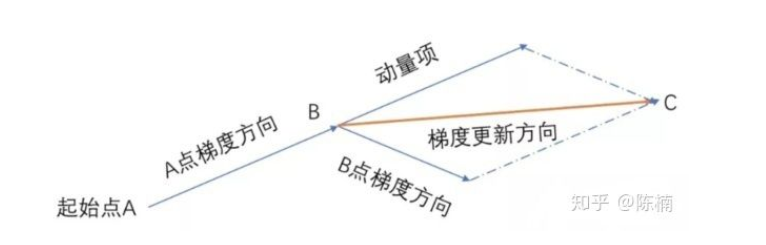
物理学中,用变量v表示速度,表明参数在参数空间移动的方向即速率,而代价函数的负梯度表示参数在参数空间移动的力,根据牛顿定律,动量等于质量乘以速度,而在动量学习算法中,我们假设质量的单位为1,因此速度v就可以直接当做动量了,我们同时引入超参数B公测,其取值在【0,1】范围之间,用于调节先前梯度(力)的衰减效果,其更新方式为:

根据上面的随机梯度下降算法给出动量随机梯度下降算法

如果衰减率为0,那么它与原版梯度下降完全相同。如果衰减率是1,那么它就会像我们开始提到的无摩擦碗的类比一样,前后不断地摇摆; 你不会想要这样的结果。通常衰减率选择在0.8-0.9左右,它就像一个有一点摩擦的表面,所以它最终会减慢并停止。
AdaGrad(自适应梯度算法)
前面的随机梯度和动量随机梯度算法都是使用全局的学习率,所有的参数都是统一步伐的进行更新的,上面的例子中我们是在二维权值的情况,如果扩展到高维,大家可想而知,那么优化环境将很复杂
AdaGrad其实是对学习率进行了约束
AdaGrad是将每一维各自的历史梯度的平方叠加起来,然后更新的时候除以该历史梯度值即可。


分母添加平滑项,防止除零操作
AdaGrad使的参数在累积的梯度较小时(<1)就会放大学习率,使网络训练更加快速。在梯度的累积量较大时( > 1)就会缩小学习率,延缓网络的训练,简单的来说,网络刚开始时学习率很大,当走完一段距离后小心翼翼,这正是我们需要的。
但是这里存在一个致命的问题就是AdaGrad容易受到过去梯度的影响,陷入“过去“无法自拔,因为梯度很容易就会累积到一个很大的值,此时学习率就会被降低的很厉害,因此AdaGrad很容易过分的降低学习率率使其提前停止,怎么解决这个问题呢?RMSProp算法可以很好的解决该问题。
RMSProp
然而,AdaGrad 的问题在于它非常慢。这是因为梯度的平方和只会增加而不会减小。Rmsprop (Root Mean Square Propagation)通过添加衰减因子来修复这个问题。
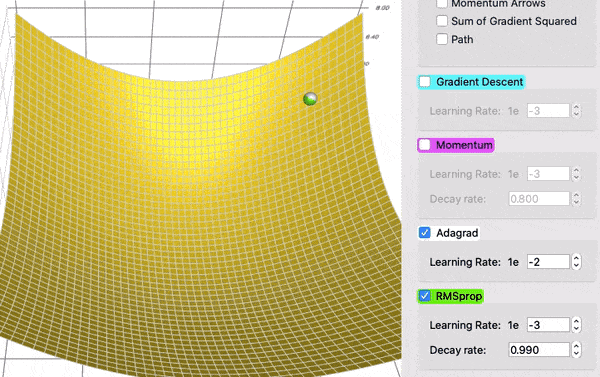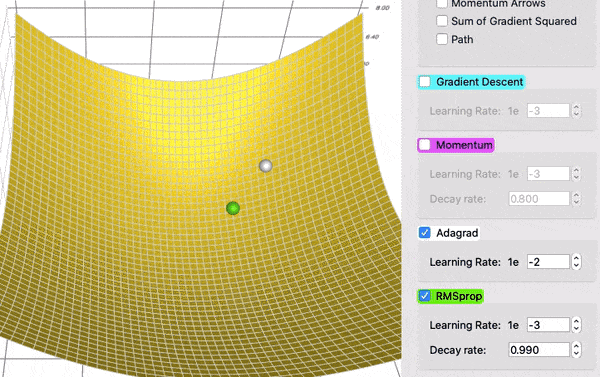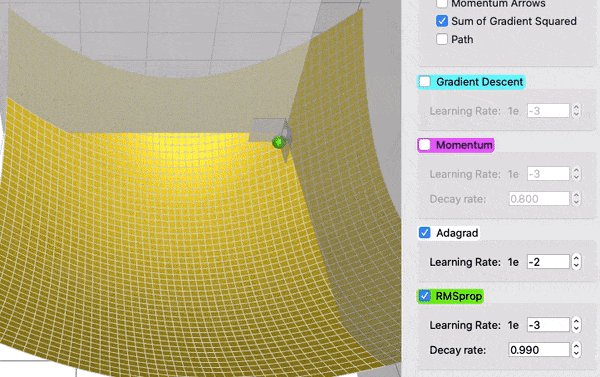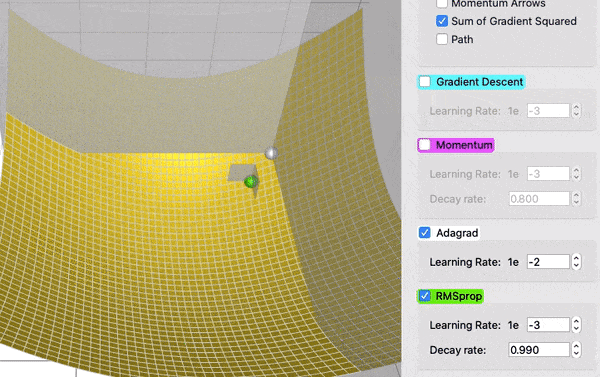
在这个对比中,AdaGrad (白色)最初与 RMSProp (绿色)差不多,正如调整学习率和衰减率的预期。但是 AdaGrad 的梯度平方和累计得非常快,以至于它们很快变得非常巨大(从动画中方块的大小可以看出)。买路费负担沉重,最终 AdaGrad 几乎停止了。另一方面,由于衰变率的原因,RMSProp 一直将方块保持在一个可控的大小。这使得 RMSProp 比 AdaGrad 更快。
数学原理:
AdaGrad在理论上有些较好的性质,但是在实践中表现的并不是很好,其根本原因就是随着训练周期的增长,学习率降低的很快。而RMSProp算法就在AdaGrad基础上引入了衰减因子,如下式,RMSProp在梯度累积的时候,会对“过去”与“现在”做一个平衡,通过超参数进行调节衰减量,常用的取值为0.9或者0.5。
RMSprop

Adam(自适应动量优化)
我们已经看到RMSProp和动量采用对比方法。虽然动量加速了我们对最小值方向的搜索,但RMSProp阻碍了我们在振荡方向上的搜索.Adam通过名字我们就可以看出他是基于动量和RMSProp的微调版本,该方法是目前深度学习中最流行的优化方法


