




写本文的起因,是前段时间手头的模型在尝试调整训练数据平衡性、更改模型结构都无法再提高准确率情况下,由于模型运行的硬件条件限制,不能再增大参数量,所以想到了知识蒸馏的方法,把整个学习过程记录一下。如果你有模型训练的基本知识,即使从来没用过知识蒸馏,也能看懂本文。
学习的第一步很自然在网上查找关于知识蒸馏的基本知识,绝大部分文章都讲解的知识蒸馏开山之作,即2015年Hinton的《Distilling the Knowledge in a Neural Network》,也是知识蒸馏主流的方法。但该文章到现在已经六年了,业界肯定不断摸索和扩展了更多的方法,惊喜地发现悉尼大学陶大成团队和伦敦大学合作于2021年3月发表了一篇全面的关于知识蒸馏综述的文章,共36页,所以第二步就是学习这篇综述文章,都不用去找额外的论文了。本文把上面两步学习的重点内容列举一下。
近年来机器学习在各个方面都取得了突破,最主要的原因是因为深度学习全面开花,在很多领域都比传统方法有了质的飞跃,但同时带来模型参数量大的问题,极端的像GPT、BERT这样的大模型,就算小点的模型,动辄参数量几十兆、上百兆,很多生产环境对模型大小有严格的限制,比如嵌入式设备,算力和存储空间都很小,就需要在尽量保证高准确率情况下减小模型,即需要进行模型压缩。
知识蒸馏是模型压缩的一种方法。
基本原理是用已有的训练数据训练一个大模型,称为教师模型(Teacher Model),然后使用一个小的模型去学习教师模型,这个小的模型就叫学生模型(Student Model)。如果学生模型准确率能接近教师模型,或者比直接使用训练数据训练学生网络结构得到的模型准确率更高,由于学生模型表教师模型小,便可达到压缩模型的目的。
这个过程相当于把知识从教师模型蒸馏出来,赋予学生模型,所以形象的叫知识蒸馏,当然蒸馏也和下面要讲到的温度参数T有关,因为蒸馏需要温度。
这下我们要回到Hinton的论文。
典型的深度学习模型最后会输出logits,比如通过Dense层或CNN层得到的输出。以分类问题为例,对logits使用softmax得到属于各个标签类别的概率值,如果有C类,那么一个输入就得到一个长度为C的softmax输出,概率值最大对应的类别就是该输入所属的类别,例如softmax输出中第i个值最大,这个输入就被认为属于第i个类别。实际训练时是拿这个softmax输出去逼近one-hot的标签向量,这个one-hot标签叫hard target。
如果一个教师网络在训练集上已经学好了一个模型,对于一个样本数据,我们可以用学生网络去学习教师模型对于该样本的输出,该输出叫soft target。hard target(one-hot)标签向量在所属类型位置值为1,其余位置为0,soft target(softmax)在所属类型位置值最大,其他位置值可能很小,但不为0,代表了属于每种类型的可能性,所以让学生网络去学习教师模型的soft target会学习得更具体。
其实早在2006年,Rich Caruana在第12届ACM SIGKDD会议上发表的文章中就使用学生网络去学习教师模型的logits。Hinton的论文则去学习教师模型的softmax,学习的方式有创新性,引入了蒸馏(distillation)的概念。
先看看下面这个用于知识蒸馏的softmax公式:
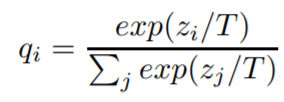
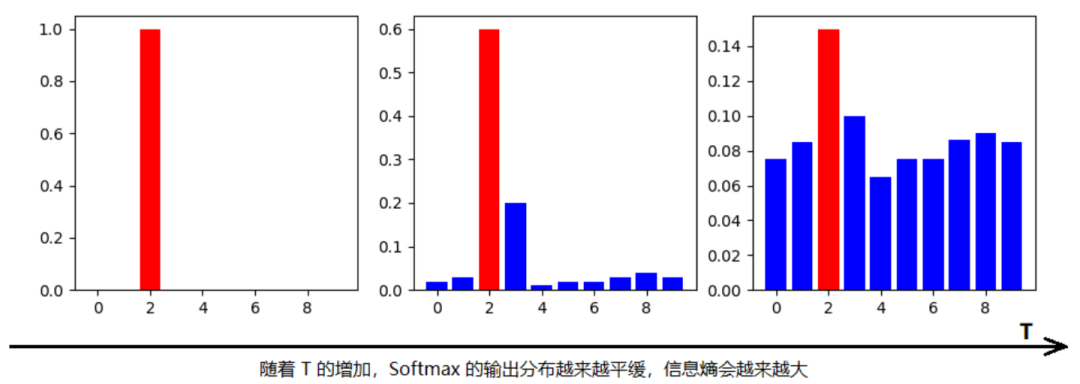
其中zi表示样本的logit输出中第i个分量的值,qi表示属于第i类的概率。和常见的softmax公式比, 多了一个参数T,称为温度,这也是为啥叫知识蒸馏的原因之一,用温度把知识蒸馏出来。对于同样的z,T越大q越平滑。下面(来自网络)是对同一个z,one-hot向量的hard target和带温度T参数的soft target输出,T越大各个分量值之间的差异越小。
Hinton论文中,让学生网络同时学习soft target和hard target效果更好,所以loss分两部分,一部分学习soft target,另一部分学习hard target,二者通过一个权重参数λ控制比例,通常情况下soft target的loss比重大一些,即更偏向于学习soft target,总结起来整个训练和预测过程如下图(来自网络):

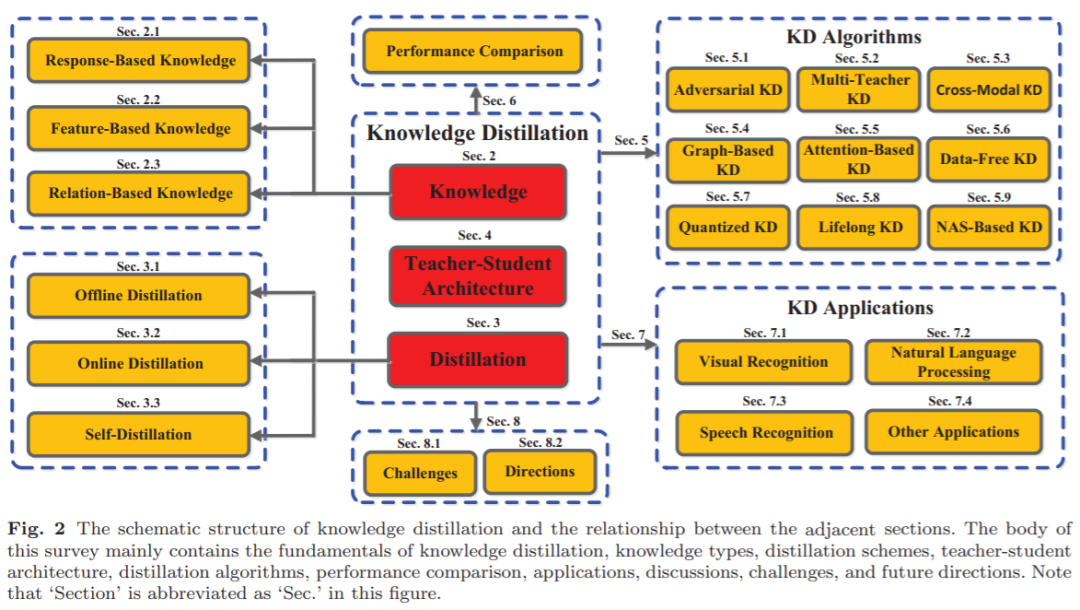
上述Hinton的文章算是开创了知识蒸馏整个领域,接下来就开始各种发展,所以很有必要全面了解一下到目前为止近几年知识蒸馏领域的全貌,悉尼大学的综述论文为此而生,下面主要概括一下该论文的关键内容,有兴趣了解细节的请自行阅读,文末附论文地址。
全文包含七个部分,每一部分如下图虚线框,Sec表示Section。
模型压缩的四种常见方法:
模型参数剪枝或者共享
低秩矩阵分解,把高维度矩阵分解为低维度矩阵,减少参数
迁移或压缩卷积过滤器(convolutional filters)
知识蒸馏
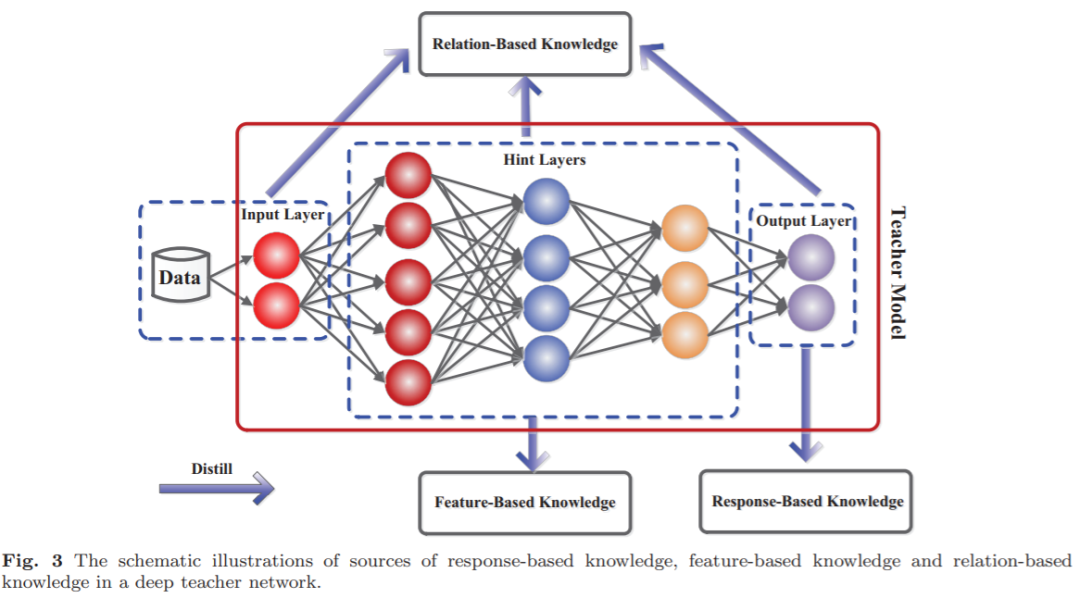
知识蒸馏先要搞清楚模型的知识在哪里。下图是典型的深度学习网络,根据在模型中的位置共分为三种知识:
Response-Based Knowledge:网络最后一层的输出,也就是Hinton论文中学习的知识
Feature-Based Knowledge:网络中间层的输出,每个输出都代表了feature representation或者feature map
Relation-Based Knowledge:不同层之间的关系也是知识
根据教师模型和学生模型是不是同时更新,知识蒸馏分为三种方法:
离线蒸馏(Offline Distillation):先训练教师模型,然后让学生模型学习教师模型
在线蒸馏(Online Distillation):教师模型和学生模型同时更新,整个知识蒸馏框架采用端到端方式训练
自蒸馏(Self-Distillation):教师模型和学生模型使用同样的网络,是在线蒸馏的一种特殊情况
知识蒸馏均使用教师-学生网络,如何设计网络结构是知识蒸馏效果好坏的关键,学生网络常见设计方法:
教师网络的简化版本,减少层数或者层内的channel数
教师网络的量化版本
一个含高效基本算子的小网络
经过全局优化的小网络
和教师网络相同
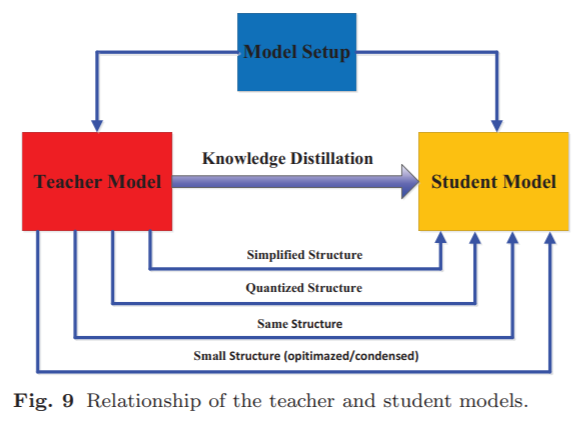
最常见的方式都是学生模型直接学习教师模型,目前主要的蒸馏算法包括:
对抗蒸馏:使用生成对抗网络(GAN),生成器和判别器之间对抗学习。
多教师模型蒸馏:学生模型向多个教师的集成模型(ensemble model)学习。
跨模型蒸馏:比如教师模型是处理文本的模型,学生模型是处理视觉的模型等。
基于图的蒸馏:使用图携带的知识,或者使用图控制教师模型消息传输,熟悉图神经网络的比较容易理解。
基于attention的蒸馏:例如使用attention map函数映射教师模型到学生模型的feature embedding。
无训练数据(data-free)蒸馏:由于隐私、安全等原因,无法获取训练学生网络的数据,训练数据需要从新生成,比如使用GAN生成或者根据教师网络的参数生成等。
量化蒸馏:把高精度教师模型转换为低精度学生模型再训练。
终身(lifelong)蒸馏:持续不断的学习。
NAS-Based蒸馏:NAS即Neural Architecture Search,使用AutoML自动搜素网络结构学习。
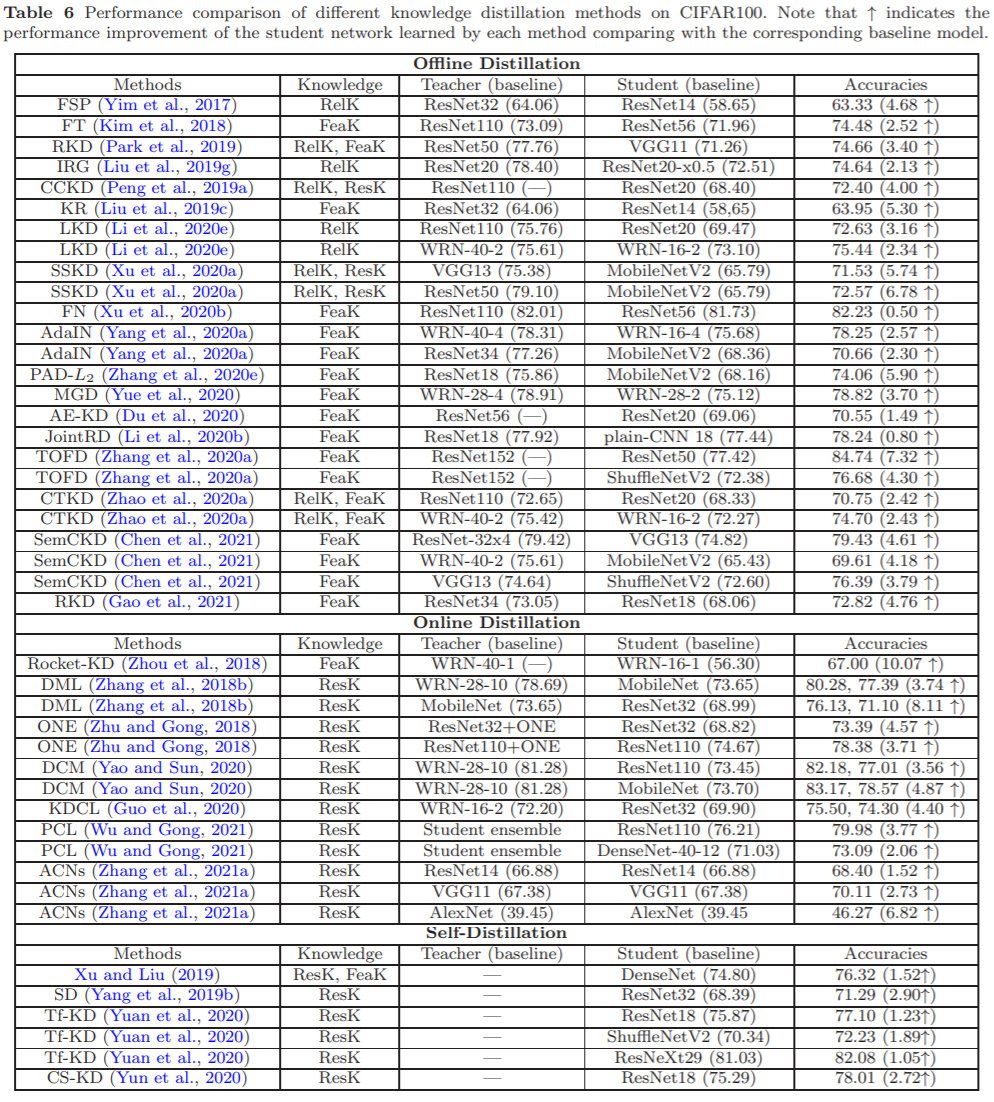
下图是各种知识蒸馏模型的性能比较,结论包括:
可以在各种深度学习模型上实现知识蒸馏
知识蒸馏可以压缩各种深度学习模型
在线蒸馏和自蒸馏均可显著改进模型性能
离、在线蒸馏通常独自进行feature-based knowledge和response-based knowledge蒸馏
总之,知识蒸馏是一种可行且有效的模型压缩方法。
论文列举了知识蒸馏广泛应用的几个领域:
Visual Recognition:图像分类、人脸识别、图像分割、目标检测等你能想到的视觉方面的应用都有。
NLP:近年来NLP取得主要成就的BERT、GPT等模型都是建立在大规模预训练模型基础上的,进行模型压缩十分必要和迫切。
Speech Recognition:语音识别模型通常需要部署到嵌入式设备上,进行模型压缩也很有必要,常见的对序列模型如RNN,CTC进行蒸馏。
其他:推荐系统在各种系统中占有重要的地位,知识蒸馏也应用广泛,此外,还有些涉及隐私和安全场景的应用。
以上是综述论文的主要内容,文中每个部分都整理了大量的参考论文,对某些部分感兴趣的同学可以有针对性地具体学习。
我自己在使用基于教师模型最终输出进行蒸馏实验,即Hinton论文的基本方法,目前还在不断实验研究中。
附:
Hinton知识蒸馏论文:
https://arxiv.org/pdf/1503.02531.pdf
悉尼大学知识蒸馏综述论文:
https://arxiv.org/pdf/2006.05525.pdf
