




上一篇系列之二介绍了早期的混合模型,底层使用GMM或者DNN计算帧对应的音素概率,上层使用HMM寻找最优的音素序列,得到最终的文字序列。该模型的缺点:
1. 需要对帧级别打标签、建模,这对语音数据来说工作量巨大,并且标签不一定准确,特别是两个音的边界部分;
2. 两个或者多个模型混合增加了模型复杂度,使用不太方便。
于是后来新的模型思路转向从语音直接预测文字,即端到端模型。今天我们来看看具有里程碑意义的CTC模型以及在其基础上改进的RNN Transducer模型,简称RNN-T模型。
CTC模型细节
CTC模型是Alex Gaves等人在2006年提出的,原始论文见http://www.cs.toronto.edu/~graves/icml_2006.pdf,要解决的是不等长序列到序列的预测问题,不仅用于语音识别,还可用于手写识别、翻译等问题。模型的主要结构仍然使用RNN,但是由于输出序列长度不再和输入序列一致,这是混合模型和端到端模型的一个主要区别,解决问题的关键是要找到一个合理的损失函数来正确衡量不等长的输出。下面我们一步步来解释。
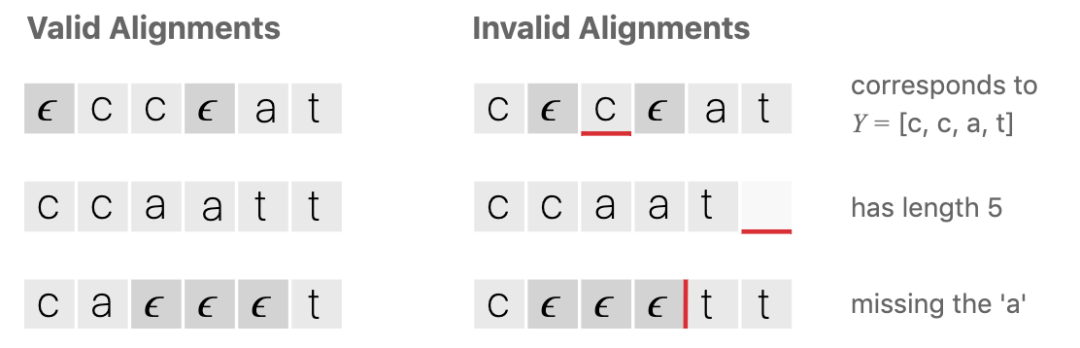
首先,CTC使用了一种新的输出方式,在标签集合中增加了一个空白标签,如下图第一行中的ϵ。把输出中的相邻重复的字符合并,然后去掉空白符,就得到了最后的文本结果。

容易看到,以前输出中每一帧必须要对应其所属的音素,现在不必一一对应,某些预测的位置用空白符代替,只要通过合并和去空白符后最终的文本正确即可。
下面以单词 cat 为例,列出一些无效的输出序列例子。需要强调的一点,含空白符的输出序列长度是固定的。
上面介绍了模型的输出方式,论文使用的RNN建模,输出维度为(batch_size, time_step, number_of_class),对batch中的每一个数据,输出为固定的时间步长度time_step, 每一步输出是一个向量,长度为所有类型种类+1,通过softmax后最大的位置对应的类型表示该步输出的类型。以上面hello中的e为例,表示第3时间步输出为e,可通过softmax后得到。这里强调两点:1)CTC的端到端并不是RNN模型直接就输出不等长的文本,输出的是含空白符的固定长度序列。2)每个时间步输出的向量长度比以前不含空白符时多1,因为增加了空白符。
说完模型输出,现在说说标签。对每个数据,标签就是最终的文本序列,比如如果语音是30帧的“你好”,标注的标签就是“你好”两个字。这是名副其实的端到端、变长序列到序列问题。那么如何计算固定长度输出到实际变长标签之间的损失函数呢?这就是CTC算法的核心。
对一条数据,所有时间步计算的结果串起来得到输出序列A,去重和空白符后即得到一个序列结果B。容易得知,有多种不同的A序列,通过去重和空白符后可得到同一个B。对于一个序列标签B,模型训练的目的就是以最大的概率找到各种正确的A,因为任何一个正确的A都可以得到B。
上述过程转换为数学语言:

X表述输入序列, Y表示标签序列,模型目标是最大化 p(Y|X)。
对每一种正确的序列A,时间步t对应的输出为a(t),所有时间步概率的乘积为X条件下该序列A的概率。所有正确的A对应概率的和即为p(Y|X)。
为方便计算,最终的损失函数转为最小化p(Y|X)的负对数
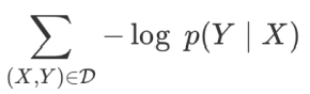
定义好损失函数后,接下来的步骤就和普通深度学习的方法一样了,通过梯度下降求RNN模型的参数。但实际计算时为减少开销,论文中使用了前后向算法,具体细节请参照论文中的详细推导。
模型实验结果
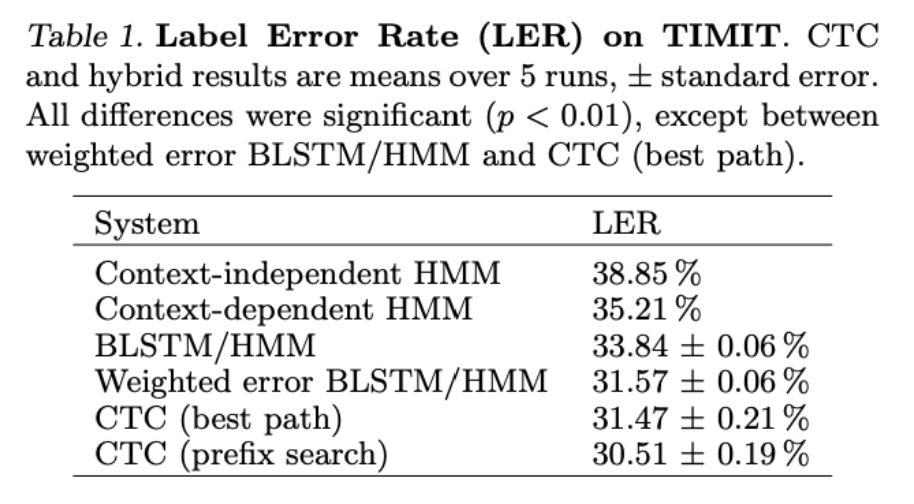
以下是论文中基于TIMIT数据集测试的结果,主要对比基于HMM的模型的LER,均有不同程度的性能提升。
实战使用
Tensorflow有现成的CTC损失函数接口可用,但要理解其参数的结构不是那么直观,这里以Tensorflow 1.13中的tf.nn.ctc_loss()为例,说一下重要的参数。
tf.nn.ctc_loss(
labels,
inputs=None,
sequence_length=None,
preprocess_collapse_repeated=False,
ctc_merge_repeated=True,
ignore_longer_outputs_than_inputs=False,
time_major=True,
logits=None)复制
其中labels是真实的标签,在此版本中只支持SparseTensor格式,指定标签的indices,value和shape,即哪些位置有真实的标签值,其余位置值为0。
inputs是模型的输出,如果是RNN网络,就是直接输出格式(batch_size, time_steps, classes_num),如果RNN网络是时间步优先,参数time_major设置为True,输出格式为(time_steps, batch_size, classes_num)。
sequence_length是inputs里每条数据实际有效长度,是一个batch_size大小的向量。
Tensorflow 1.13还提供了另一个版本tf.nn.ctc_loss_v2(),是上面版本preprocess_collapse_repeat=True和ctc_merge_repeated=Flase的特例,更重要的一点是labels支持Dense Tensor,即直接传入labels矩阵就行,不用再构造SparseTensor。
实际使用CTC时你会看到网络输出的logits里有大量的空白符,每个标签连续输出的情况不多,我理解为只有大量的空白符情况下才能使各种正确的输出序列概率最大。
备注:百度语音识别的两个版本Deep Speech 1和2均使用了CTC。
RNN Transducer模型
从CTC的结构可以看出其没有明确学习序列时间步之间的关系,比如读音/greɪt/ 应该拼成 great 或 grate,但 CTC 可能拼成不合理的 grete。为了加入时间步前后间的关系,就出现了RNN Transducer模型。
该模型同样是CTC的作者Alex Graves于2012年提出的(能提出多个厉害的模型,强悍!),论文见:https://arxiv.org/pdf/1211.3711.pdf。从下图可以直观看出Transducer模型和CTC的区别。

Transducer主要是在CTC的基础上把模型Encoder的隐藏层输出联合另一个输出,这个被联合的输出是最终模型的某一个输出经过Pred Network计算的结果。本质的意思是在CTC模型上加入了序列之间的关系。Pred Network作者用的LSTM。
Transducer的损失函数和CTC一样的思路,但是在训练的时候比CTC复杂,因为Pred Network中的u和Encoder中的时间步t有很多种组合。具体方法在论文中有详细的推导,同样用了前后向算法。
Transducer实验结果
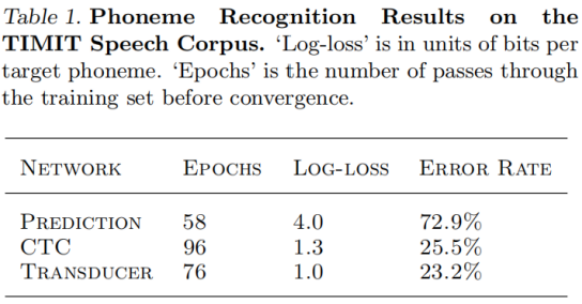
作者同样基于TIMIT数据对Transducer和CTC进行了比较,性能提升不多,解释原因是Pred Network使用的数据不多,可以使用基于大量数据预训练一个Pred Network来提高准确度。
此外,Google 2019年使用Transducer模型压缩后应用于移动设备上,逐个字符实时输出单词,有效减少输出延时, 详见:https://ai.googleblog.com/2019/03/an-all-neural-on-device-speech.html
总结
本文介绍了CTC及RNN Transducer模型的主要结构和思路,希望对你有些帮助。对于模型中的一些细节,比如前后向算法,需要阅读原论文推导才能慢慢消化。另外对于Tensorflow CTC损失函数的使用,也要边用边理解。
