




1
要解决的问题
NLP模型训练中经常需要训练大量的文本数据,如果把所有数据存入一个文本文件中,则对文件的读和写都需要消耗很大的内存,数据过大甚至内存不够用;如果把数据存入太多文件、每个文件含数据很少,则打开关闭文件操作太频繁,以上两种方法效率都很低。恰当的方法是把数据存入多个文件,每个文件大小适中。例如总体有1000万条数据,可以存入10个文件,每个文件100万条。
那么训练过程中如何高效地读取这样的多个大文本文件呢?有效的方法是一个一个文件读取,而不是把所有数据都装载到内存中,否则耗费内存太多影响系统性能,数据过多则内存不够用,出现Out Of Memory问题。
此外,通常情况下我们需要在读取数据的过程能进行动态增广(例如随机选择部分数据进行删除、重复、替换等)和shuffle。
本文根据我自己工作中已经验证过的方法,分享在Tensorflow和Pytorch中的实现细节,前提是你对Python中的生成器generator有一定了解。
2
总体思想
要对多个文件逐个读取,常用的方法是使用Python中的generator,每次装载一个文件,一行行读取返回,读完一个文件再装载下一个,直到所有数据都读取完。有关generator的细节不是本文的重点,如果需要了解的请自行学习。
Tensorflow比较好处理,其接口支持直接从generator获取数据,我们只需要创建一个读取多个文件的generator,然后调用Tensorflow接口即可。
Pytorch接口不支持从generator直接读数据,需要做一些转换,网上看有不少人有这样的需求提问,很多回答没有给出有效的答案,这是本文想重点分享的内容。
3
Tensorflow实现
定义一个generator,循环读取文件夹中每个文件,进行数据增广和shuffle,然后每次yield一条数据。文件的具体读取我只写了一个伪代码方法read_data_from_file(file_path),每个项目中根据自己的存储格式读取。一般情况下把一个文件装载入内存进行处理不会消耗太多内存,不会有性能问题。
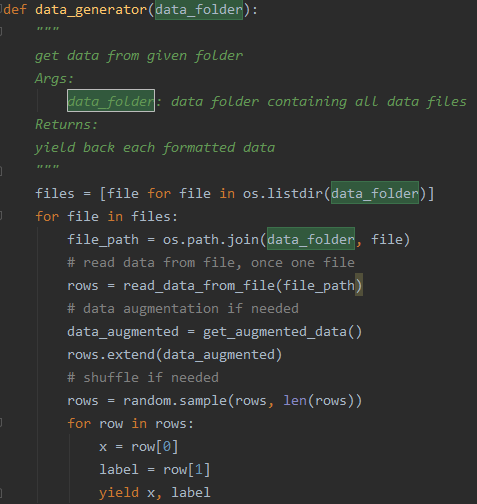
训练代码直接使用tf.data.Dataset.from_generator()从generator中读取数据。

tf.data.Dataset本身有shuffle的接口,此处我们在generator中使用shuffle只是增加一种shuffle的方法,读者可以根据自己的需要选择。
4
Pytorch实现方法一:Map-style datasets
Pytorch提供了torch.utils.data.DataLoader()从Dataset里读取数据,详见:https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
Dataset分两种类型,Map-style datasets 和 Iterable-style datasets。
Map-style datasets需要实现__getitem__(index) 和 __len__() 两个方法,__getitem__(index)常用的方法是给定一个index,返回对应的value,这样torch.utils.data.DataLoader()就可以从__getitem__(index)中源源不断读取数据。__len__()方法返回数据的总数,torch.utils.data.DataLoader()读取完这个数据量的数据后就结束,读取中可指定shuffle=True进行自动shuffle。
此方法面临的问题:使用此方法一般需要把所有数据或者数据的索引装载进内存,比如图像处理或者语音识别中,把所有需要处理的图像或者wav数据id list读进内存,__getitem__(index)每次根据一个id再具体读对应的图像或者wav数据进内存,内存开销不大。但是NLP中通常是很多数据放在一个文本文件中,并不是一条数据存一个文件,所以不能类似只读id list进内存。但如果把所有数据读进内存又会出现内存使用过多或者Out Of Memory问题。
解决方法:仍然使用和Tensorflow方法中相同的generator,__getitem__(index)中每次返回generator中的一条数据,但是由于__len__()方法必须要实现,在generator读取完数据前并不知道一共有多少数据,可以以一种快速的方法,比如使用linux wc命令获取数据总数,在初始化Dataset class时传入。
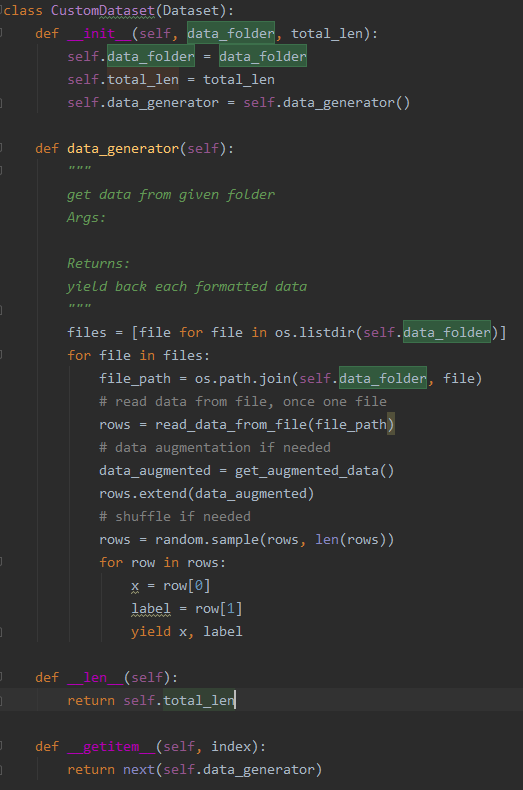
训练时使用方法:

此方法不合理之处在于调用Dataset时要传入数据总量,按理说我们调用Dataset时只需给数据文件路径,Dataset返回所有数据,不需要我告诉它一共有多少数据。所以有下面更合理的方法。
5
Pytorch实现方法二:Iterable-style datasets
Iterable-style datasets只需要实现__iter__()方法,该方法返回一个iterable的对象,torch.utils.data.DataLoader()读取的时候不断从该对象中读数据,不需要像上面Map-style datasets方法要指定数据总量。
此方法面临的问题:该方法可能由于对后面读取的内容未知,所以不支持shuffle=True参数。
解决方法:仍然使用和Tensorflow方法中相同的generator,__iter__()直接返回这个generator,由于我们在generator中已经实现了自动增广和shuffle,所以不存在增广和shuffle的问题,也不需要像上面Map-style datasets一样要传入数据总量,全部文件数据读完了就结束,完美!
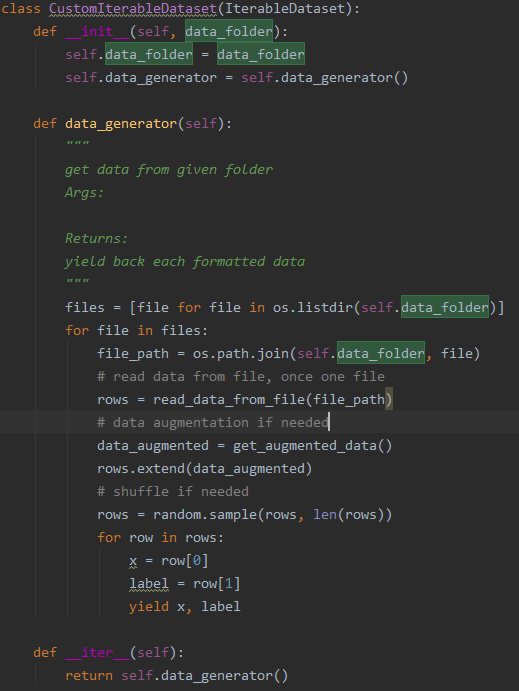
训练时使用的方法:

6
总结
Tenforflow支持直接从generator读数据,简单方便。Pytorch还得转一下,且iterable-style dataset的方法不支持shuffle,其实Pytorch应该像Tensorflow一样实现一个支持generator的接口。
有了上面的方法,你便可以从容使用Tensorflow或者Pytorch从海量大文本文件中读取数据了,不用担心内存不够的问题。
