




近两年对比学习是机器学习中研究的一个热点,作为我知识版图中的一块,对近期的学习做个总结。
常见的机器学习分类方法把机器学习分为监督学习、无监督学习、半监督学习,主要区别是训练数据有无标签。
无监督学习即训练数据没有标签,这里的无标签指的是不需要人为地加标签,不管是手动还是其他方法标注,典型算法如聚类算法。自监督学习本质属于无监督学习,训练数据不需要标注,直接用来训练,只不过训练过程中使用数据自身的内容作为学习目标,也可以说是从自身找标签。
根据不同的学习目标,自监督学习可分为三类:
基于上下文的方法:NLP中的word2vec模型,通过句子中两边的词预测中间的词,这个中间词就是学习的标签,不需要人工标注,同样通过中间词预测两边的词也一样。还有著名的BERT模型,随机遮住一些词,然后预测遮住的内容,均属于基于上下文的自监督方法。
基于时序的方法:主要指音频或者视频这类有时间先后顺序的场景,相邻时刻的内容具有相似关系,可以学习这种相似关系,也不需要人工标注。
基于对比的方法:从无标注数据中选择数据做变换或增强,源数据和变换或增强后的数据互为正例,和其他数据互为负例,训练过程中对比正例和负例,让正例之间距离靠近并拉开负例之间的距离。
上面说了这么多自监督的内容,是因为本文的主角对比学习属于自监督学习的一种。那么一般如何使用自监督学习呢,或者说用自监督学习来解决什么实际问题呢?目前大部分场景是用自监督学习从海量的无标注数据中学习数据的特征表示,常叫representation或者embedding,对于给定的数据,有了特征表示就可以用来训练各种下游任务,比如分类问题、序列标注问题等,总之所有能用到向量来进行训练的问题!
NLP中使用BERT在大规模无标签数据上进行预训练,同时使用Transformer结构,可以说是具有里程碑式的意义,并且在工业界各个领域内实实在在地落地应用,取得了相当的成功。自然地,CV中能否用类似的思路来解决图像相关的问题成了大家研究的重要方向,这是近年来对比学习火热的主要原因。
对于文本数据,有典型的上下文关系或者时序关系,容易构建模型来学习这种上下文或者时序关系。但对于图片,上下文关系不明显,也无时序关系,于是大家想到了对图片进行增强,常见的增强方法包括旋转、放大缩小、变色等,增强后的图片和源图片相似,互为正例,源图片和其他图片不相似,互为负例,然后构建模型通过学习这种相似性和不相似性,让模型有从数据中提取特征的能力。
要做好对比学习,主要要解决以下问题:
如何构建正例和负例数据,使得数据更多样化、更合理。
模型结构设计,让模型更好地提取到数据的特征。
损失函数设计,让正例间距离越近、负例间距离越远,并避免模型坍塌(Collapse),即避免不同输入通过模型计算后映射到了同一个值。
距离函数,上述损失函数中用到的距离计算,使用什么函数更合理。
各种层出不穷的对比学习模型主要是在想办法改进上面四个问题。文章剩余部分先介绍最经典的两个基础对比学习模型,然后介绍NLP领域近两年对比学习相关的主要论文,有了这些知识,在实际工作中就可以根据需要进一步研究,选择恰当的模型使用、扩展。
对比学习开始火热,主要始于两个模型,何凯明团队的MoCo模型和Hinton团队的SimCLR模型,两个模型又分别进化了多个版本,下面分别介绍。
MoCo(https://arxiv.org/pdf/1911.05722.pdf)是Momentum Contrast首字母的缩写,即动量对比,核心是动量更新key encoder网络的参数值,下面我们具体解释。
MoCo或者说很多对比学习模型的目的就是构造一个字典,模型训练好后字典就构造好了,对于任何一个输入,从字典中查询的结果就是我们需要提取的特征。这个和NLP的embedding类似,如果以word为单位,对每个word就可以从word embedding中查询到特征表示。只不过对图像来说,不像NLP中的word那样可以穷举,需要想别的办法。
先直接看MoCo的结构:
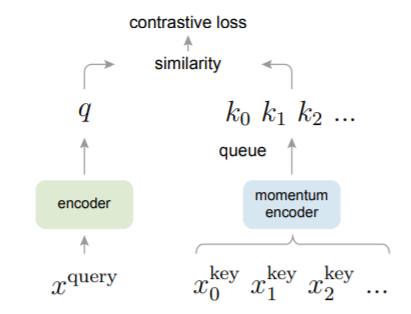
再结合对应的Pytorch伪代码理解:

有两个分别针对query和key的encoder网络f_q和f_k,通过网络后的结果就相当于从字典查询到的结果。
对输入x,分别做不同的增强得到x_q和x_k,通过f_q和f_k后得到的q和k互为正例,可以得到正例的loss。
维护一个负例的queue,当前的q和queue中所有数据互为负例,可计算得到当前batch负例的loss。联合已经得到的正例loss就是当前batch的整体loss。
每次得到整体loss后还有两件事情要做:
通过动量更新方法,使用f_q更新f_k。
把当前batch的k放入负例queue,最早batch的k从queue中删除,使得queue不断平滑更新,保持一致性,不至于变化太剧烈。
所以MoCo的特色就是维护了一个不断更新的负例queue,同时key encoder不断通过query encoder平滑动量更新。
了解MoCo核心后再挑几个重点说说:
1)和其他模型结构的比较
论文比较了MoCo和end-to-end以及memory bank结构,唯一区别就是key encoder部分。
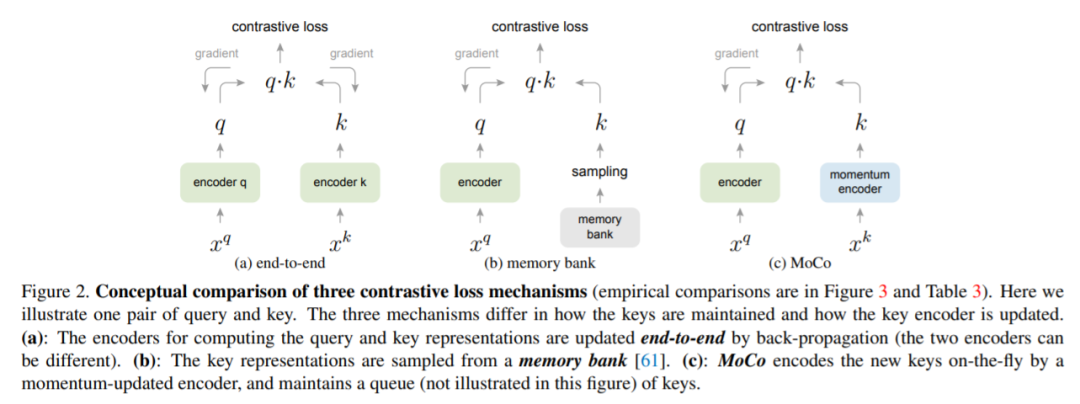
end-to-end结构两个encoder通过反向传播单独更新,二者的参数可以相同也可以不同,重点是每次字典就是通过当前batch数据查询,所以字典大小受限于当前batch数据大小,一般来讲,大的字典比小的字典好,MoCo使用多个batch数据,字典更大。
Memory bank维护一个包含所有数据的memory bank,每个mini-batch随机从中采样负例数据,比MoCo需要更多内存开销,并且memroy bank中内容更新没有MoCo更新得及时和平滑。
2)encoder网络结构
使用ResNet。
3)损失函数
使用对比学习常用的InfoNCE损失函数:
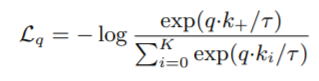
q是f_q查询的结果,ki是f_k查询的结果,k+是f_k中唯一一个和q匹配的正例,T是温度超参数。分子表示q和k+的距离,距离越近,值越大,loss越小,分母表示负例间距离,距离越远,值越小,loss越小。达到了拉近正例、拉开负例间距离的目标。
4)动量更新公式
f_k参数通过f_q的动量更新公式:
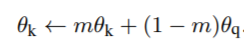
m是一个权重系数,实验证明大点的m,比如0.999,比小点的值,比如0.9的效果更好,m越大,参数更新越平缓。
SimCLR(https://arxiv.org/pdf/2002.05709.pdf)提出比MoCo稍晚,结构更简单明了:
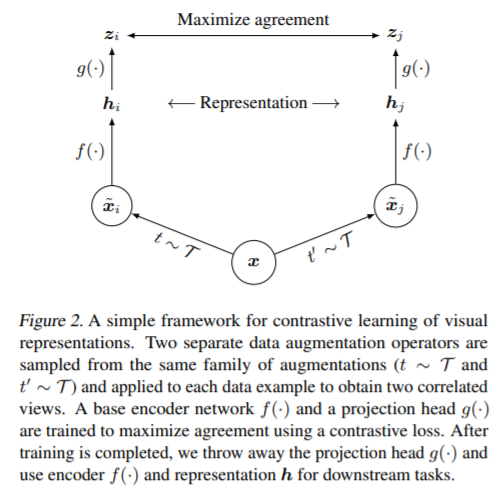
逻辑上和之前描述的对比学习思路相同,包括以下几步:
数据增强:随机使用三种增强方法,裁剪、翻转、变色,同一batch中N张图片都做增强,通过同一个张图片增强后的两张图片互为正例,其余情况互为负例。
Encoder网络:两个分支使用相同的网络,论文中也使用ResNet。
Projection网络:使用全连接网络。
损失函数:和InfoNCE类似
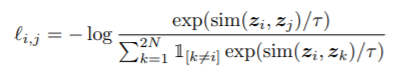
其中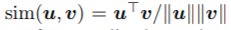 ,即cosine相似度。
,即cosine相似度。
更直观点的图如下(源自知乎张俊林):
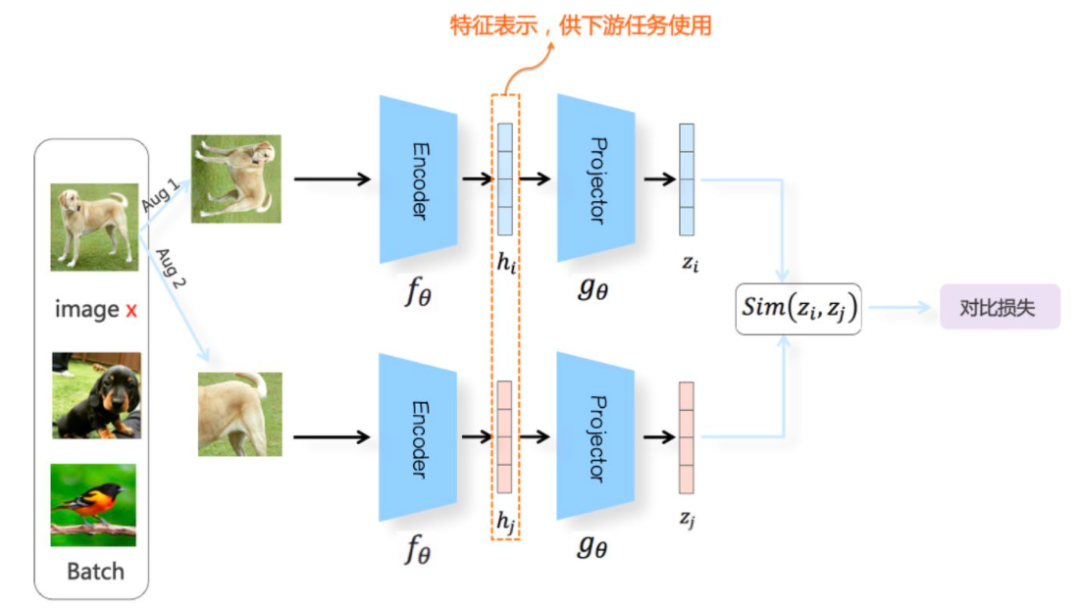
算法描述如下:

论文重点对batch size大小、模型大小、数据增强方法、projection非线性层、损失函数对模型影响做了实验对比和分析。
MoCo和SimCLR各自出了第一个版本后,分别又出了新的版本改进,互相借鉴,各个版本的主要变化如下(源自知乎张俊林):
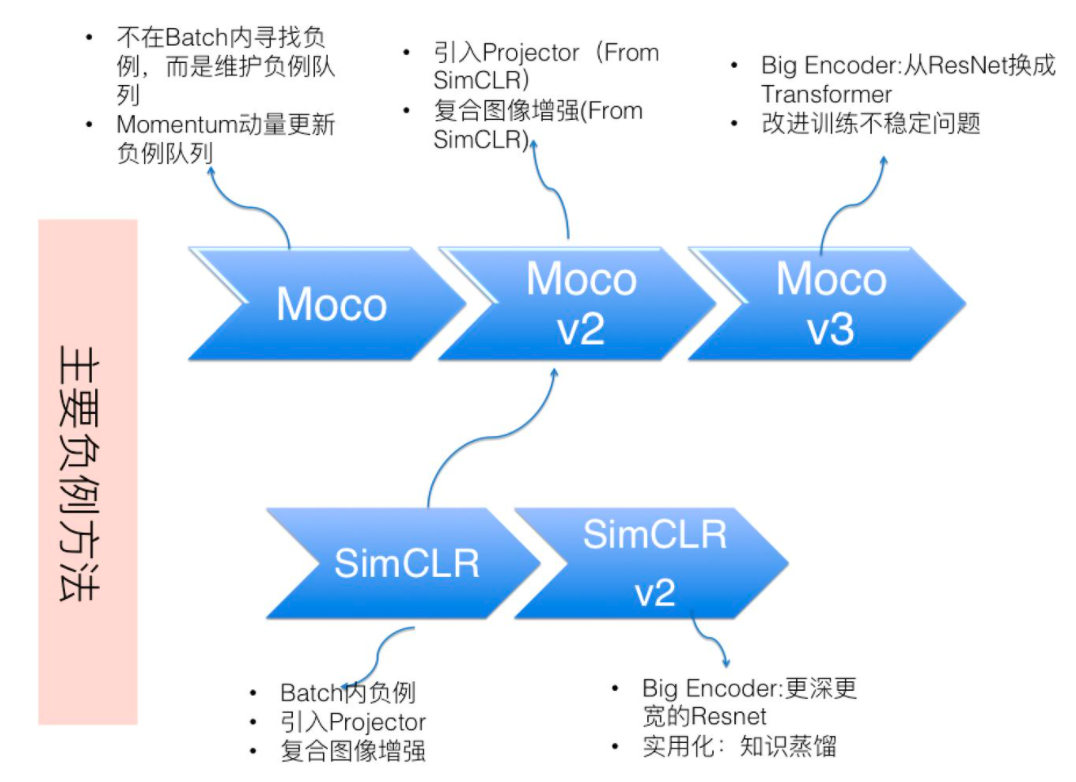
除了上述两个经典的模型,常见的模型还有引入聚类的SwAV模型,只使用正例的BYOL、Barlow Twins模型等。
本文开头提到, 由于NLP领域自监督学习的成功,CV领域开始研究,带火了对比学习。随着CV领域对比学习的火热,NLP领域也开始尝试如何使用对比学习,所谓我中有你,你中有我,互相学习,不断向前发展。
我平时的工作更多在于NLP方面,所以整理下NLP中部分对比学习论文:
1)CERT
https://arxiv.org/pdf/2005.12766.pdf
解决BERT类预训练模型定义于token级别,不能很好第捕捉句子级别语义的问题,在句子级别使用对比学习,用回传方式做数据增强。
2)CLEAR
https://arxiv.org/pdf/2012.15466.pdf
也是基于句子级别的对比学习,数据增强的方法使用字或者文本段(span)的删除、重排序或者替换。loss联合了MLM loss和对比学习的loss。
3)SimCSE
https://arxiv.org/pdf/2104.08821.pdf
先使用了无监督学习,对比学习部分只使用dropout作为数据增强方法就取得了不错的效果,负例在batch内取。然后进行了有监督学习及比较。
4)SCL
https://arxiv.org/pdf/2011.01403.pdf
监督的对比学习,在预训练模型微调阶段联合交叉熵和自定义的SCL loss,具体loss如下:
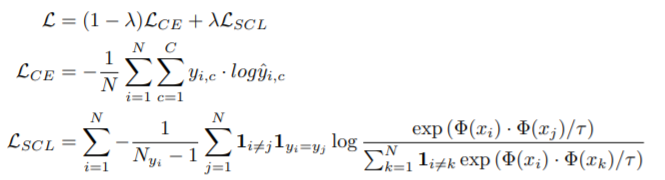
实验结果显示在测试集上好于RoBERTa-Large模型的基线模型性能。
5)DeCLUTR
https://arxiv.org/pdf/2006.03659.pdf
数据增强方法从每个文档中取A个anchor文本段 (anchor span),
训练时每个anchor有一个正例span,其余span之间互为负例。不同span的长度用Beta分布决定。loss联合MLM loss和对比学习loss。
最后,谈点自己的感悟。学术界虽然按照研究对象和解决问题的不同分了不同的领域,其实在理论层面的本质都是相通的。一个理论在一个领域碰出了点火花,会迅速在其他领域燎原起来,最近我们在ASR中也在调查看能否用对比学习解决一些问题。相关论文层出不穷,对工业界来说,怎么把已有的理论联系实际问题,并落地解决问题最重要。
参考文章:
对比学习研究进展精要,张俊林
https://zhuanlan.zhihu.com/p/367290573
对比学习在CV与NLP领域中的研究进展,对白
https://zhuanlan.zhihu.com/p/389064413
对比学习在CV,NLP,MM的应用,胡安文
https://zhuanlan.zhihu.com/p/378456417
