




1 简介
TuGraph 是费马科技自主研发的图数据库产品。其主要特点是单机大数据量,高吞吐率,以及灵活的 API,同时支持高效的在线事务处理(OLTP)和在线分析处理(OLAP)。 LightGraph是TuGraph的曾用名。
主要功能特征包括:
支持属性图模型
原生图存储及处理
完全的ACID事务支持
支持OpenCypher图查询语言
支持原生的Core API和Traversal API
支持REST和RPC接口
支持CSV、MySQL等多数据源导入导出
支持可视化图交互
支持命令行交互
内置用户权限控制、操作审计
支持任务和日志的监控管理
原生适配PandaGraph图分析引擎
性能及可扩展性特征包括:
支持TB级大容量
吞吐率高达千万顶点每秒
面向读优化的存储引擎
支持高可用模式
支持离线备份恢复
在线热备份
高性能批量导入导出
2 安装
TuGraph可以通过Docker Image快速安装,或者通过rpm/deb包本地安装。
2.1 通过Docker Image安装
对于拥有Docker的用户,我们推荐通过Docker Image来启动TuGraph。
获取TuGraph镜像的命令如下:
$ docker pull fmacloud/lgraph:latest
如果用户不能直接访问外网,可以通过网盘下载docker镜像,然后上传到服务器上。如:
$ wget https://fma-ai.cn/download/lgraph_latest.tar
$ docker load -i lgraph_latest.tar
启动Docker的命令如下:
$ docker run -d -v {host_data_dir}:/mnt -p 7090:7090 -it fmacloud/lgraph:latest
$ docker exec -it {container_id} bash
其中 -v 是目录映射,{host_data_dir}是用户希望保存数据的目录,比如/home/user1/workspace。 -p的作用是端口映射,例子中将Docker的7090端口映射到本地的7090端口。{container_id}是Docker的 container id,可以通过 docker ps 获得。
一些可能碰到的问题:
CentOS 6.5版本不支持高版本的Docker,需要安装Docker 1.7.0 版本。
如果要在非sudo模式下使用docker,需要先将用户加入到docker用户组 sudo usermod -aG docker {USER} ,并刷新用户组 newgrp docker。
2.2 通过rpm/deb包安装
我们提供CentOS的rpm包和Ubuntu的deb包,同时可以适配SUSE、银河麒麟等类UNIX操作系统,如有需要联系文末的技术支持。
3 使用 TuGraph 服务
本小节以Docker提供的环境为例,从Movie和IoT两个场景的介绍如何使用TuGraph服务。
3.1 Movie场景
Movie场景的数据和脚本在 ~/tugraph_demo/movie目录下
3.1.1 建立模型
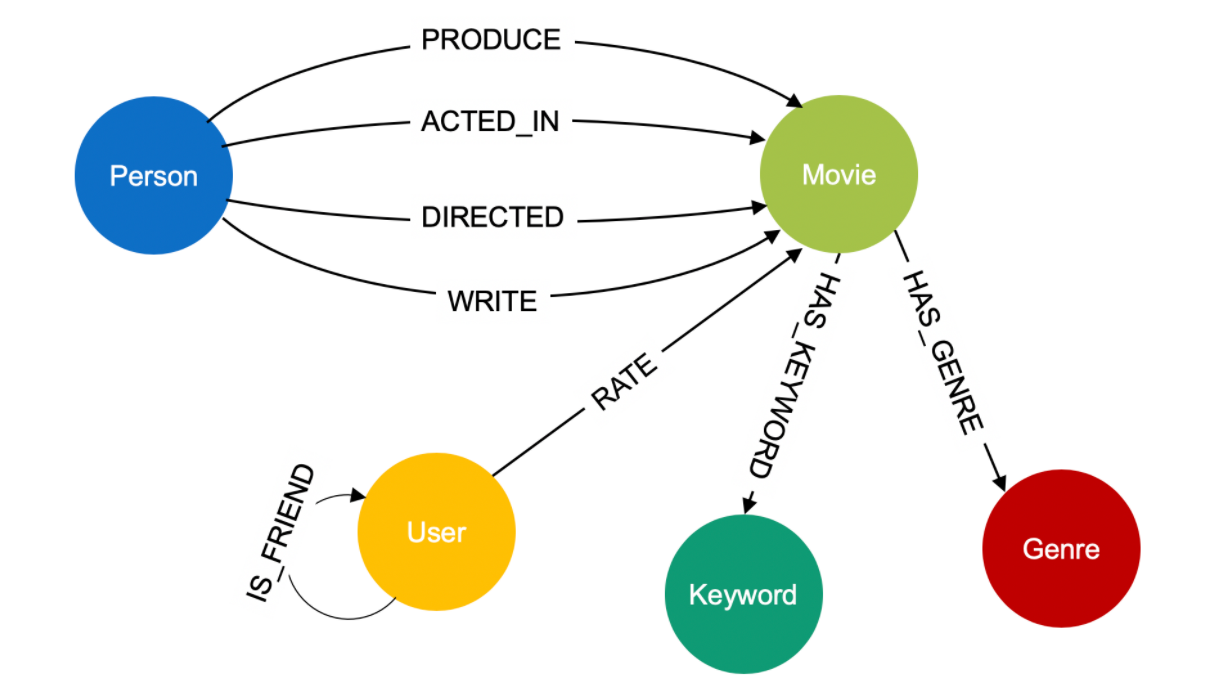
如上图所示,影视数据共包含5种实例,8种关系,共同描述电影和演员的基本关系,以及用户对电影的评分。
movie 实例。表示某一部具体的影片,比如"阿甘正传"。
person实例。表示个人,对影片来说可能是演员、导演,或编剧。
genre实例。表示影片的类型,比如剧情片、恐怖片。
keyword实例。表示与影片相关的一些关键字,比如"拯救世界”、”虚拟现实“、”地铁“。
user实例。表示观影的用户。
produce关系,连接person和movie。表示影片的出品人关系。
acted_in关系,连接person和movie。表示演员出演了哪些影片。
direct关系,连接person和movie。表示影片的导演是谁。
write关系,连接person和movie。表示影片的编剧关系。
has_genre关系,连接movie和genre。表示影片的类型分类。
has_keyword关系,连接movie和keyword。表示影片的一些关键字,即更细分类的标签。
rate关系,连接user和movie。表示用户对影片的打分。
is_friend关系,连接user和user。表示用户和用户的好友关系。
3.1.2 导入数据
$ bash import.sh
脚本会根据 配置文件,将图数据从csv数据文件导入。
acted_in_rels.csv friends_rel.csv has_genre_rels.csv keyword_node.csv person_node.csv ratings.csv writer_of_rels.csv directed_rels.csv genre_node.csv has_keyword_rels.csv movie_node.csv produced_rels.csv user_node.csv
3.1.3 启动服务
$ lgraph_server --license /mnt/fma.lic --config ~/tugraph_demo/movie/lgraph.json
fma.lic是授权文件,应放在{host_data_dir}文件夹中,映射到docker的/mnt下。lgraph.json是TuGraph的配置文件。
3.1.4 查询入口
TuGraph提供基于浏览器的可视化查询和基于命令行的交互式查询。
如果使用基于浏览器的可视化查询,网页地址为 {IP}:{Port},默认用户名为 admin,密码为 admin123456。注意端口需要浏览器能直接访问,如果在Docker内需要做端口映射。然后我们可以在浏览器中输入127.0.0.1:7090进行访问。
如果使用基于命令行的交互式查询,需要使用lgraph_cypher工具,查询的示例在 ~/tugraph_demo/movie/query目录下。
3.1.5 查询示例
我们将Movie数据导入图数据库后,可以非常方便地进行增删查改的操作,由于图数据的数据表达方式和传统的关系数据库不同,不能简单的用SQL进行查询,TuGraph采用Open Cypher作为主要的查询语言。Open Cypher是一个面向图数据的开放标准,是目前工业界认可度最高的图查询语言之一。
以下的操作的实例可以在浏览器或命令行操作。
示例一
查询影片 ‘Forrest Gump’ 的所有演员,返回影片和演员构成的子图。
MATCH (m:movie {title: ‘Forrest Gump’})<-[:acted_in]-(a:person) RETURN a, m
示例二
查询影片 ‘Forrest Gump’ 的所有演员,列出演员在影片中扮演的角色。
MATCH (m:movie {title: ‘Forrest Gump’})<-[r:acted_in]-(a:person) RETURN a.name,r.role
示例三
查询 Michael 所有评分低于 3 分的影片。
MATCH (u:user {login: ‘Michael’})-[r:rate]->(m:movie) WHERE r.stars < 3 RETURN m.title, r.stars
示例四
查询和 Michael 有相同讨厌的影片的用户,讨厌标准为评分小于三分。
MATCH (u:user {login: ‘Michael’})-[r:rate]->(m:movie)<-[s:rate]-(v) WHERE r.stars < 3 AND s.stars < 3 RETURN u, m, v
示例五
给Michael推荐影片,方法为先找出和Michael讨厌同样影片的用户,再筛选出这部分用户喜欢的影片。
MATCH (u:user {login: ‘Michael’})-[r:rate]->(m:movie)<-[s:rate]-(v)-[r2:rate]->(m2:movie) WHERE r.stars < 3 AND s.stars < 3 AND r2.stars > 3 RETURN u, m, v, m2
示例六
查询 Michael 的好友们喜欢的影片。
MATCH (u:user {login: ‘Michael’})-[:is_friend]->(v:user)-[r:rate]->(m:movie) WHERE r.stars > 3 RETURN u, v, m
示例七
通过查询给’Forrest Gump’打高分的人也喜欢哪些影片,给喜欢’Forrest Gump’的用户推荐类似的影片。
MATCH (m:movie {title:‘Forrest Gump’})<-[r:rate]-(u:user)-[r2:rate]->(m2:movie) WHERE r.stars>3 AND r2.stars>3 RETURN m, u,m2
3.2 IoT场景
IoT场景的数据和脚本在 ~/tugraph_demo/iot目录下
3.2.1 建立模型
平均而言,人一生中有80%的时间待在建筑物中。智慧建筑通过分析处理建筑内的数据,自动控制照明,通风,空调以及安全等管理系统,为用户提供更高效,更可持续,更安全,更舒适的建筑环境。智慧建筑使用的数据由数量众多的传感器/智能装置提供,它们相互连接,并实时与监控和数据采集系统交互,为智慧建筑系统提供基础设施和数据。
在本例中我们使用Brick作为建筑数据的模型。建筑物中的实体表示为Brick模型中的节点。每个实体都是某个类的实例,实体之间可以建立关系。这些类在可扩展的层次结构下定义,类之间的层次关系如下:

类之间的关系模型如下:

以上的Point, Location, Equipment等是Brick模型中的高级类,它们的含义如下:
- Point类:Points是产生时序数据的实体,这些实体可以是物理的也可以是虚拟的。物理points包括建筑中实际的传感器和设置点,而虚拟points包含对其他时序数据处理得来的综合数据,比如楼层平局温度传感器。
- Equipment类:Equipments受points控制,为特定任务设计的物理装置。例如灯,风扇和AHU等。
- Location类:建筑物中具有各种粒度的区域。 例如房间,楼层等。
例如,一个简单的建筑模型如下所示:

import.sh 脚本会根据 import.config 配置文件,将图数据从csv数据文件导入。
3.2.2 导入数据
$ bash import.sh
$import.sh$ 脚本会根据 $import.config$ 配置文件,将图数据从csv数据文件导入。
3.2.3 启动服务
$ lgraph_server --license /mnt/fma.lic --config ~/tugraph_demo/iot/lgraph.json
fma.lic是授权文件,应放在{host_data_dir}文件夹中,映射到docker的/mnt下。lgraph.json是TuGraph的配置文件。
3.1.4 查询入口
TuGraph提供基于浏览器的可视化查询和基于命令行的交互式查询。
如果使用基于浏览器的可视化查询,网页地址为 {IP}:{Port},默认用户名为 admin,密码为 admin123456。注意端口需要浏览器能直接访问,如果在Docker内需要做端口映射。然后我们可以在浏览器中输入127.0.0.1:7090进行访问。
如果使用基于命令行的交互式查询,需要使用lgraph_cypher工具,查询的示例在 ~/tugraph_demo/movie/query目录下。
3.2.5 查询示例
物联网中各个物体相互连接,相互作用,与图数据十分契合。越来越多的设备加入到物联网中,产生指数级增长的连接关系(relationships)数量,图数据库可以更直观地存储这些连接关系,更简洁高效地进行查询。
我们以Open Cypher作为查询语言演示物联网数据的操作示例。
示例一
查询所有的VAVs(variable air volume)。
MATCH (vav)-[:rdftype]->({uri:'brickVAV'}) RETURN DISTINCT vav.uri
示例二
查询所有属于zone temperature sensors及其子类的传感器。
MATCH (sensor)-[:rdftype]->()-[:rdfssubClassOf*0..]->({uri:'brickZone_Temperature_Sensor'})RETURN DISTINCT sensor.uri
示例三
查询AHU(air handler unit)的下游设备和传感器。
MATCH ({uri:'brickAHU'})<-[:rdftype]-(ahu)-[:bffeeds*..]->(x) RETURN DISTINCT x.uri
示例四
查询符合以下连接模式的floors,rooms和zones:rooms在floor之上,the HVAC zones包含rooms。
MATCH ({uri:'brickFloor'})<-[:rdftype]-(floor)-[:bfhasPart*..]->(room)-[:rdftype]->({uri:'brickRoom'}) ,({uri:'brickHVAC_Zone'})<-[:rdftype]-(zone)-[:bfhasPart*..]->(room) RETURN DISTINCT floor.uri,room.uri,zone.uri
示例五
查询所有与VAV有关的事物:它的上游及下游,它的测量点,它包含的设备。
MATCH ({uri:'brickVAV'})<-[:rdftype]-(vav)-[:bffeeds*..]->(x) ,(vav)<-[:bffeeds*..]-(y) ,(vav)<-[:bfisPointOf*..]-(z) ,(vav)<-[:bfisPartOf*..]-(a) RETURN DISTINCT vav.uri,x.uri,y.uri,z.uri,a.uri
