




平时在使用小规模数据集训练模型的时候,一般一个GPU训练一段时间就够了,但在实际项目中,当数据量不断增大,同时需要在规定的时间内训练出模型,让多GPU并行计算提高训练速度就显得尤为重要,今天我们看看并行计算的原理以及具体实现。
1
MPI和并行计算
并行计算或分布式计算,本质上是把一个计算任务分布到多个节点上计算,然后把每个节点上的计算结果汇总起来,其中的关键是如何分发任务、同步各节点信息、汇总计算结果。
不管在什么平台,使用什么编程语言,各个节点间消息传递的逻辑其实是相似的,没有必要每个平台和编程语言各自为阵重复造轮子,于是在1992年业界提出了一个统一的消息传递接口标准Message Passing Interface,简称MPI。以后各种平台若需要实现并行计算,都按照MPI规定的接口去实现节点间的消息传递即可。
2
MPI Reduce和AllReduce
MPI定义了一系列的接口,我们主要关心的是Reduce和AllReduce,负责如何分发和汇总信息。
Tensorflow中有不少reduce相关的函数,比如tf.reduce_sum(),tf.reduce_mean(),reduce顾名思义减小、缩小,就是把一个数据集合降维缩小为另一个集合,比如把一个列表求和或求平均得到一个数。
下面是一个MPI Reduce Sum的例子,为了求第一行方框中数字的和,我们把这些数字分配到4个节点0,1,2,3中,把0号节点当成中心节点,各个节点对应位置的数求和后汇总到中心节点即可。
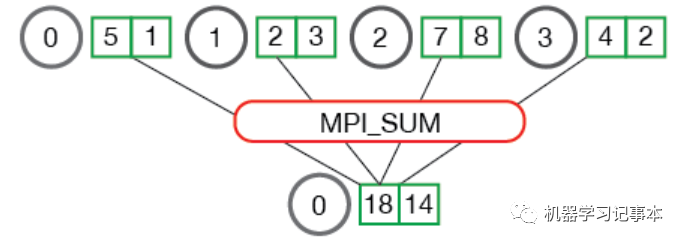
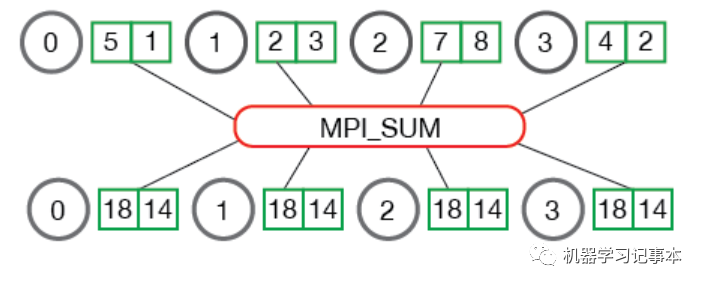
容易发现,Reduce需要一个中心节点,以上图为例,有时1,2,3号节点同样需要最后得到的和用作其他计算,显然MPI Reduce不能满足要求,于是有了下图的AllReduce。和Reduce比,AllReduce多了一个广播的动作,把计算结果广播到所有节点。
3
Ring AllReduce
上一节的AllReduce通过广播形式传递数据,节点之间的数据传输开销很大,会严重影响整个系统性能,抵消掉原本我们想通过多节点提高计算速度的效果。于是2017年百度提出了Ring AllReduce加以改进,即环形AllReduce,首先用到了百度的PaddlePaddle平台,随后Tensorflow也包含了该实现。
下面以多个GPU如何实现数组求和来说明Ring AllReduce的原理,主要包含两步,图片来自知乎。
第一步:各GPU按块求和。
首先,将数组分配在N块GPU上。
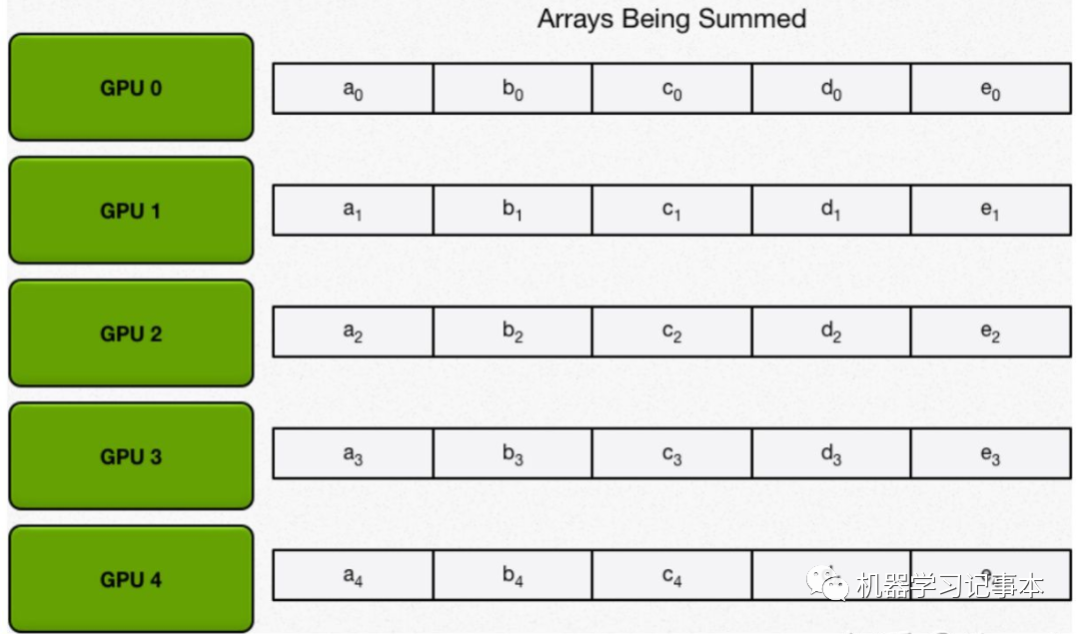
然后,进行N-1轮reduce,每一轮中每个GPU将自己的一个块发给下一邻居,并接收上一邻居发来的块做累加。
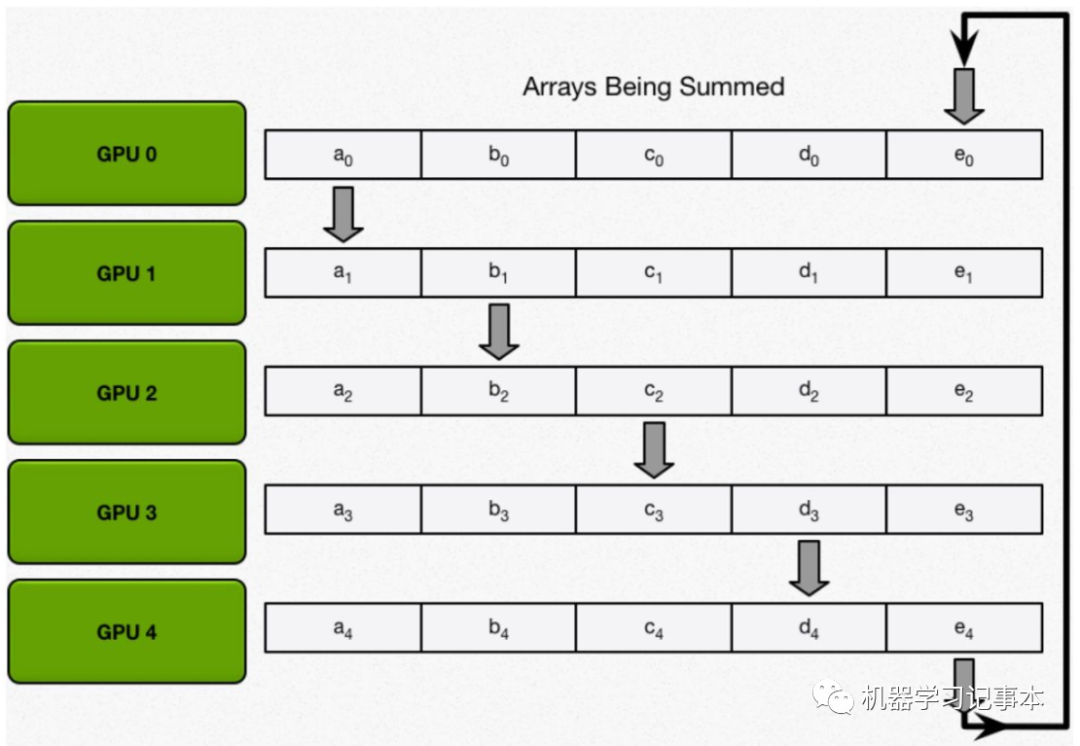
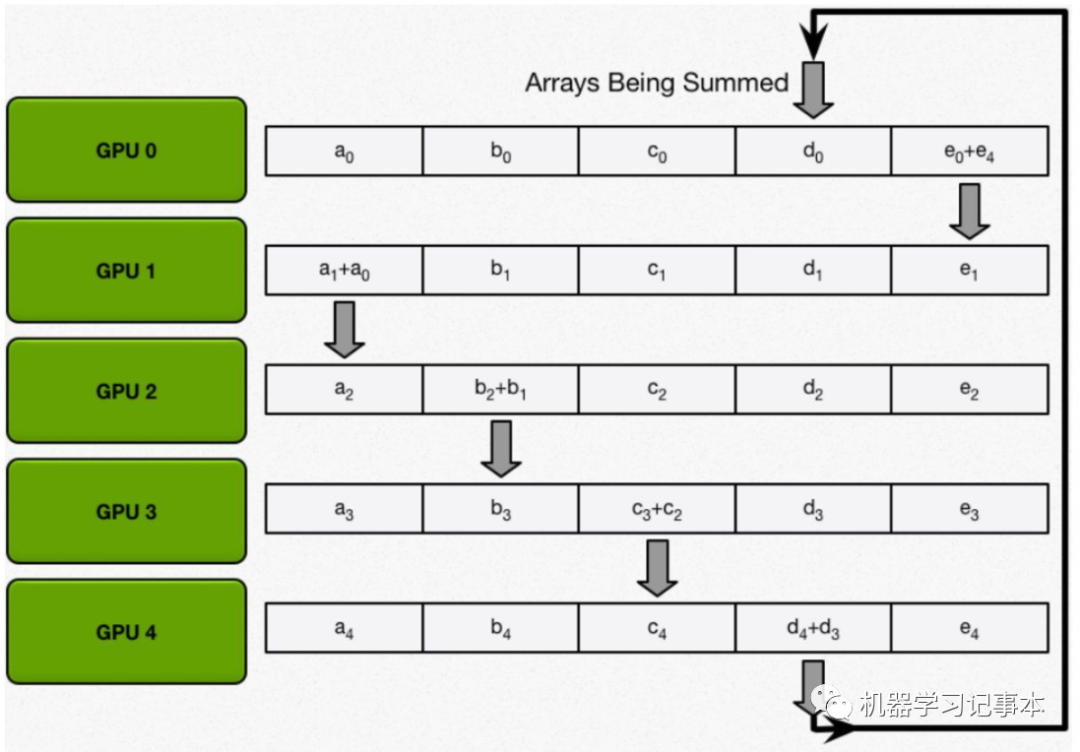
持续到第N-1轮,直到最后每个GPU中某一块含有该位置所有数据的和。
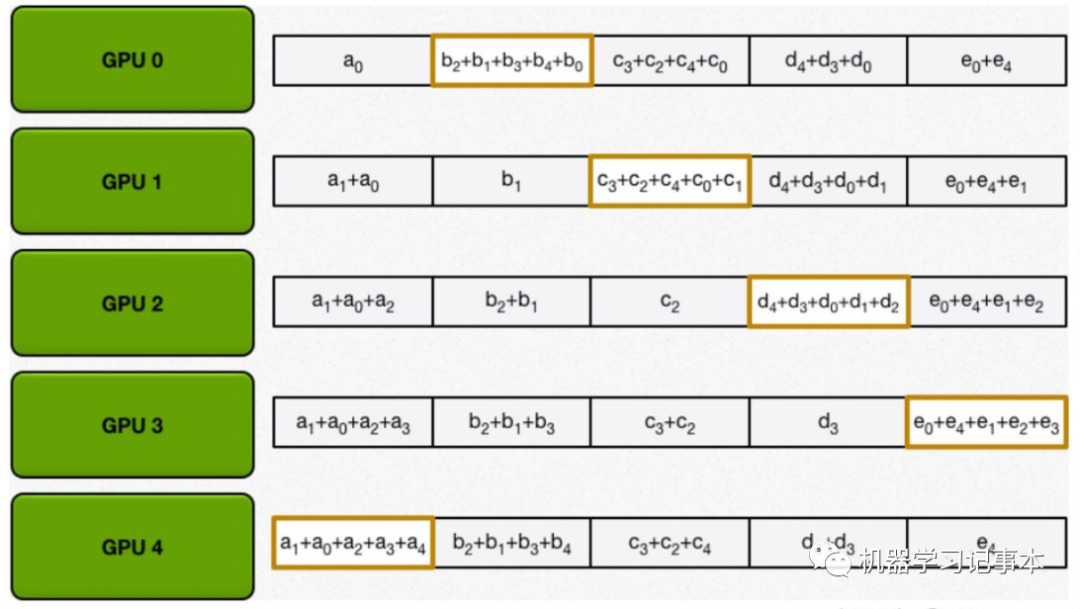
第二步:把每一块的和同步到所有GPU,方法和第一步类似,相邻的GPU不断传递。
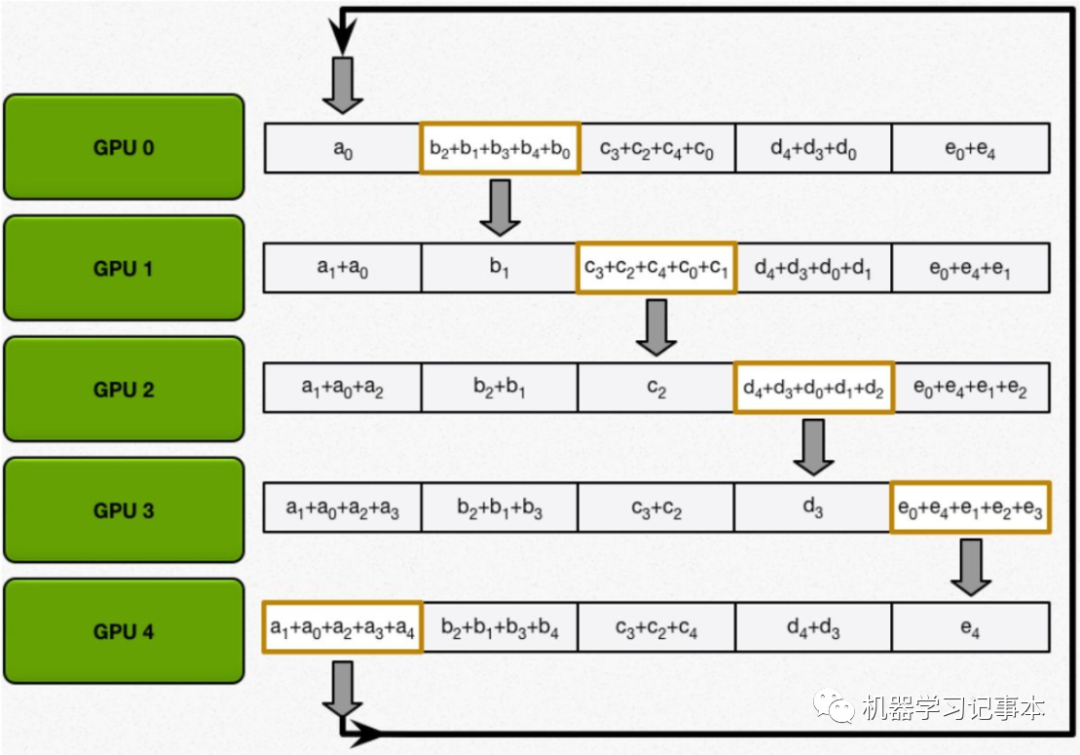
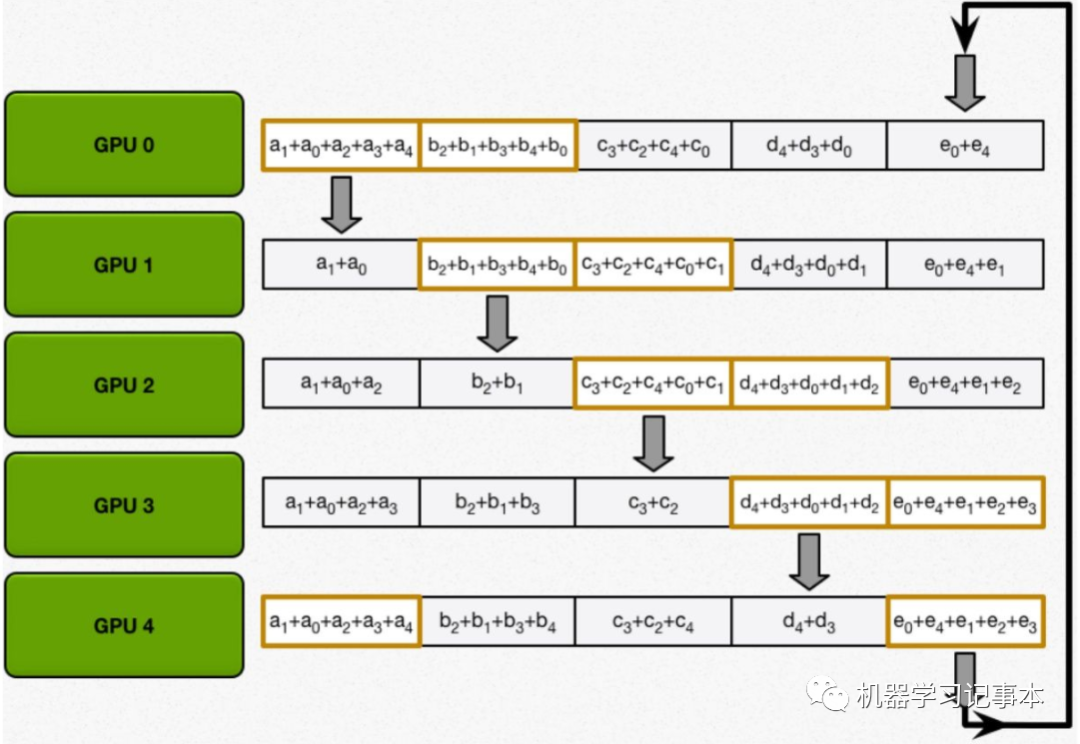
直到所有GPU都含有完整的计算结果。
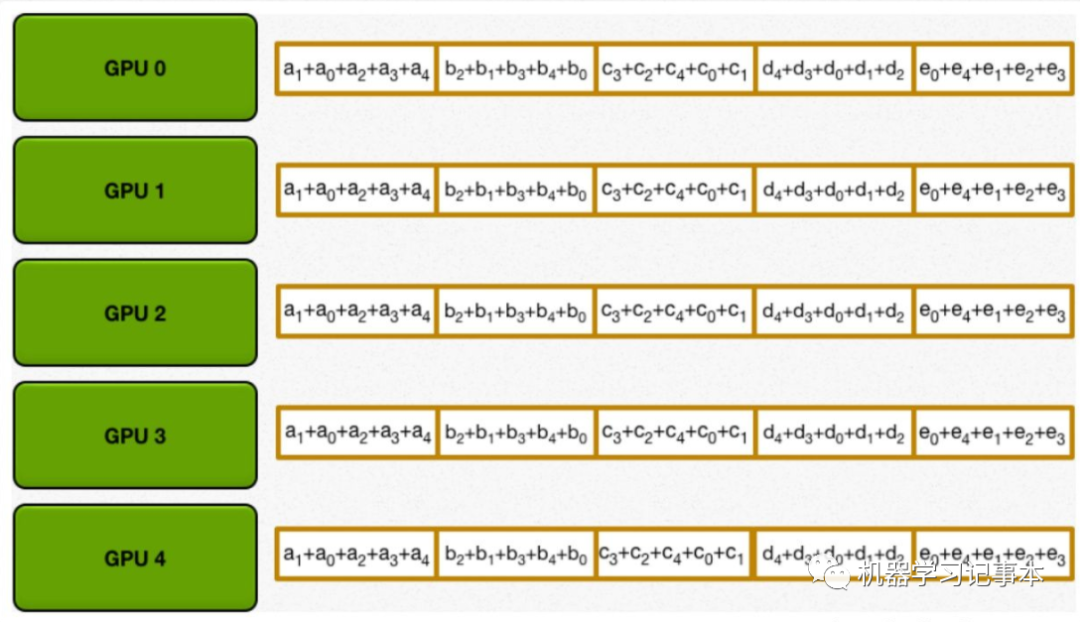
容易证明,如果要传输的数据量为K,GPU数为N,则整个Ring AllReduce过程中的数据传输开销为2(N−1)*K/N,随着N的增大,该值只和K有关,即整个系统的计算性能随GPU数量增加呈线性提高,因为数据传输开销不会受GPU数的影响,这和以前的广播传输数据有本质的区别。
对于使用多GPU进行深度学习训练,每个GPU各自进行正向传播计算,以及反向梯度计算,最终各个GPU都收到相同的梯度计算的结果汇总,然后对梯度取平均,各自进行模型权重更新,这个数据分发、计算、汇总的过程和上面的两步过程一样。
4
Tensorflow并行计算
上面搞清楚了多GPU并行计算的原理,接下来看看使用Tensorflow具体如何实现。
Tensorflow实现并行计算主要有两种方式,一是使用其自带的接口tf.distribute.Strategy,二是使用其他工具,例如Horovod,Hopsworks。
对于自带的接口,有兴趣的可直接参考https://tensorflow.google.cn/tutorials/distribute,我在自己的项目中因为之前已经使用了单GPU训练,如果使用Horovod,只需加几行代码即可实现多GPU训练,十分方便,所以本文重点分享一下使用Horovod的方式。Horovod是Uber公司开源的用于支持深度学习平台多GPU训练的工具,已支持TensorFlow, Keras, PyTorch, Apache MXNet。
5
Horovod+Tensorflow实现步骤
以下是使用Horovod和Tensorflow实现多GPU并行计算的具体步骤:
安装Open MPI
Horovod依赖于Open MPI。
从https://www.open-mpi.org/software/ompi/v4.0/ 下载tar文件,然后执行如下命令安装:
shell$ gunzip -c openmpi-4.0.0.tar.gz | tar xf -
shell$ cd openmpi-4.0.0
shell$ ./configure --prefix=/usr/local --with-cuda
shell$ make all install
安装NCCL
NCCL是Nvidia优化多GPU并行计算通信的一个库,能优化性能,具体安装步骤见 https://docs.nvidia.com/deeplearning/nccl/install-guide/index.html
安装Horovod
把NCCL路径加入环境变量,以我的环境为例:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/nccl-2.7.3:/usr/local/lib
然后和普通python包一样安装Horovod:
HOROVOD_NCCL_HOME=/usr/local/nccl-2.7.3 HOROVOD_GPU_OPERATIONS=NCCL pip install --no-cache-dir horovod
安装过程容易出现gcc编译出错:
INFO: Compiler /usr/bin/g++ (version 5.4.0 20160609) is not usable for this TensorFlow installation. Require g++ (version >=7.3.1 20180303, <999)
把gcc升级为Tensorflow依赖的gcc版本就可以了。
Tensforflow 1.x使用session模式代码
其实在原有单GPU训练代码上主要就增加如下一行,把优化器包装一下
opt = hvd.DistributedOptimizer(optimizer, op=hvd.Average)
其中op=hvd.Average表示梯度计算取各个节点计算的平均值。
注意,如果多GPU在一台机器上,一般我们只需要在一个节点上保存模型就行了,hvd.rank()==0表示在0号GPU上保存模型。同样的,若要保存Tensorboard log,也只需在一个节点上保存。
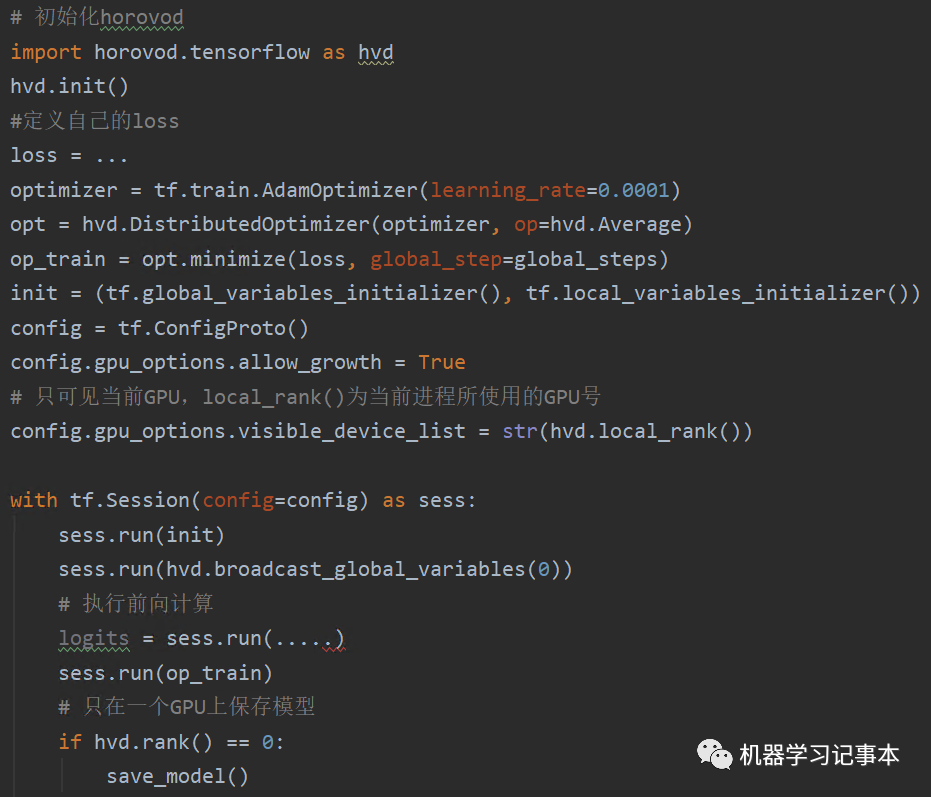
关于训练数据的分配,多个GPU训练的目的就是希望每个GPU训练不同的数据子集,最终在更短时间内训练完整个数据全集,可以使用Tensoflow的dataset接口划分不同的数据集,每个GPU根据GPU编号识别并使用各自的数据子集。
Tensorflow 2.x eager模式代码
和Tensorflow 1.x类似,只是在单GPU代码基础上对优化器做了一个包装。
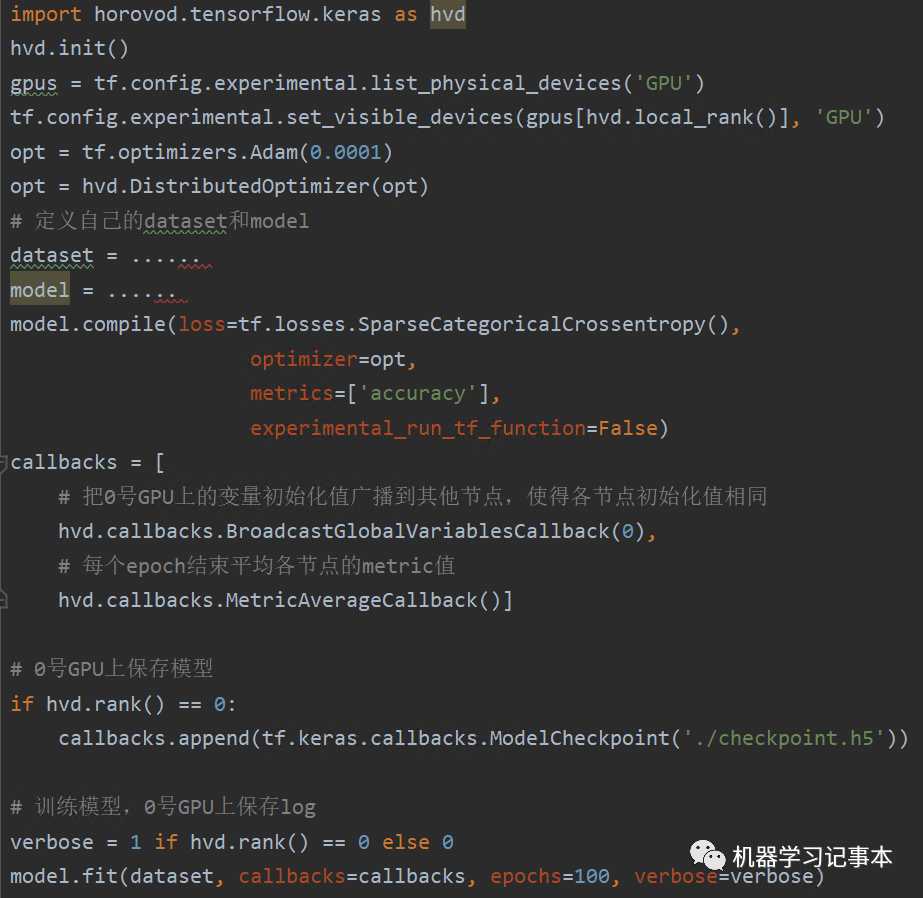
如果要自己计算梯度而不是调用fit()方法,也是同样的方式,只需对优化器进行包装,其他代码不变。
运行
一切就绪后,如果GPU在同一台机器上,运行下面命令就可以在4个GPU上并行计算了,train.py是训练的脚本。
horovodrun -np 4 -H localhost:4 python train.py
如果在4个机器上分别运行4个GPU共16个,命令如下:
horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py
目前我只实验过多GPU在同一台机器上的情况,以我的实验为例,两个GPU训练的速度是单GPU的1.36倍,3个GPU的训练速度是单GPU的2.07倍。具体性能评估请参考Horovod论文。
以上就是本文要介绍的全部内容,系统描述了并行计算的原理和Tensorflow上的具体实现步骤及代码。下次再见。
