




最近两年内,如果稍对NLP领域有所关注,你会不断看见ELMo、Attention、Transformer等相关字眼或模型。那么它们究竟在讲什么?今天我们一个一个来梳理一下。每一个模型要细讲都需要单独一篇文章讲解,这里我只对其重点进行描述,大家读完后可知道各个模型要解决什么问题以及是其解决的思路。这也是我自己学习整理的过程,如果有理解不准确的地方,欢迎指正。
备注:BERT无疑属于热门模型的一员,但由于篇幅原因,我将另行一篇文章整理。
ELMo
文本处理最基本的一步就是文本向量化,现在应用最广泛的是2013年Milolov等人提出的著名的word2vec模型,我之前有一篇文章做了详细解释,其次是斯坦福大学NLP组提出的GloVe以及Facebook提出的FastText。这三个模型的共同不足是对于给定的语料库,训练出来的向量就固定不变了,但是实际应用中,同一个词在不同语境中意思可能完全不一样,比如“买一斤苹果”和“买一个苹果手机”中的“苹果”分别表示不同的意思,如果用同一个向量表示就不恰当了。ELMo就是用来解决这种问题的模型,首先它是用来创建词向量的模型,其次它能根据具体的输入文本,联系上下文和语境动态生成相应的向量。
ELMo全称Embeddings from Language Models,顾名思义是从语言模型中学习词向量。
使用ELMo模型分三步走,这也等价于讲解模型的基本思路:
1. 预训练:在大文本库(比如维基百科文本)上训练一个深度双向LSTM(Long Short Term Memory)语言模型,对于每一个词,把深度语言模型中每层的向量表示联合起来就是该词的向量表示,最简单的情况就是只把最后一层的向量表示作为该词的向量表示。这一步的目的是基于大文本库训练得到一个语言模型。
2. 迁移:在具体要使用的预料库中,调整学习(Fine Tuning)第一步得到的语言模型,得到新的语言模型,即领域迁移学习。
3. 使用:对于要处理的文本,输入到第二步得到的新的语言模型,得到ELMo向量,然后把ELMo向量使用在你的NLP场景中。对于已经有的NLP模型,可以把ELMo向量加入模型第一个层、隐藏层或者输出层。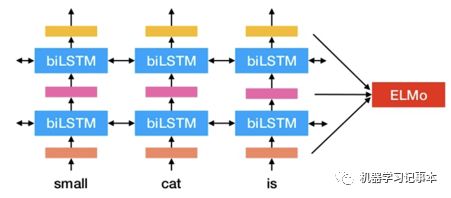
对于第一步中的预训练,可以用word2vec或者GloVe作为输入向量,加快训练。模型论文作者实验表明联合模型中多层向量表示的结果优于只使用最后一层向量表示。
论文提到语言模型中低层向量主要抓取到文本的语法信息,高层向量主要抓取到语义信息。
ELMo模型于2018年由AllenNLP研究院提出,论文见《Deep contextualized word representations》https://arxiv.org/pdf/1802.05365.pdf对于如何把ELMo用于中文,请参考文章http://www.linzehui.me/2018/08/12/%E7%A2%8E%E7%89%87%E7%9F%A5%E8%AF%86/%E5%A6%82%E4%BD%95%E5%B0%86ELMo%E8%AF%8D%E5%90%91%E9%87%8F%E7%94%A8%E4%BA%8E%E4%B8%AD%E6%96%87/
Attention
Attention机制在神经网络领域提出来有很长一段时间了,比如2011年就有论文把它用在图像识别上,不过这里我们要谈的是在NLP上的应用。
为了理解Attention机制,我们先从机器翻译系统(Neural Machin Translation, NMT)谈起。近年来最流行的机器翻译系统是基于sequence-to-sequence的模型,细节请参照我关于用机器学习写春联的文章,即源语言句子传入一个encoder,通过RNN(Recurrent Neural Network)得到一个context vector,然后通过一个decoder翻译出目标语言句子,decoder也使用RNN。
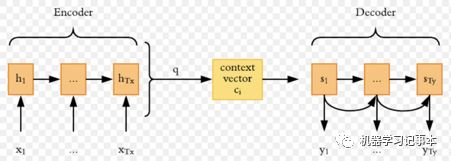
要使得decoder翻译准确,encoder的输出context vector需要尽可能包含整个输入句子的信息,对于越长的输入,越难保证context vector一个向量能抓取到所有信息。这就是Attention机制要解决的问题。
Attention机制中decoder不仅考虑encoder最后输出的向量,也考虑encoder中每一个单词对应的输出向量,也叫隐藏状态。顾名思义,Attention的意思的就是decoder在处理每个单词的时候会注意输入中的每个单词,重点注意和自己关系更紧密的单词,注意程度通过打分表示,不同模型使用不同的打分公式。下图是斯坦福NLP课程解释Attention机制的示例图。
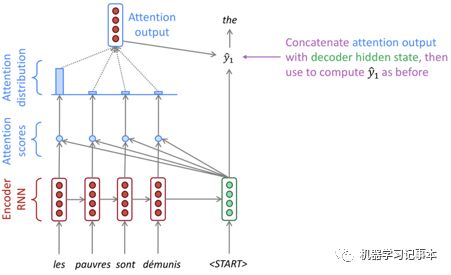
图中左边红色和蓝色部分是encoder,右边绿色部分只表示第一个隐藏层向量的处理,该向量和encoder中每个隐藏层输出向量根据打分公式计算Attention分数,然后所有分数通过Softmax算得各自概率,最后各向量和自己的概率相乘得到的所有向量相加作为Attention output。
得到的Attention output向量和decoder的隐藏层向量连接在一起组成一个新的向量,然后输入一个前馈神经网络或者其他函数求得第一个单词输出。后续的单词输出计算遵循同样的流程。
以上描述十分简要,如果要了解每一步的细节,还得读原论文或者关于Attention专门讲解的文章。Attention的两篇重要文章分别是《Effectiv Approaches to Attention-based Neural Machine Translation》https://arxiv.org/pdf/1508.04025.pdf和《Neural Machine Translation By Jointly Learning To Align And Translate》https://arxiv.org/pdf/1409.0473.pdf
Transformer
Transformer是Google在2017年提出的一个基于Attention机制的encoder-decoder模型,Google把这个模型用在了他们的翻译系统上。
Transformer没有使用传统encoder-decoder模型都使用RNN或者LSTM,主要创新点是使用了Self-Attention和Multi-Head Attention。实验结果表明该模型和传统模型比减少了计算量,提高了并行率,同时实验效果并未降低。
原论文《Attention Is All You Need》https://arxiv.org/pdf/1706.03762.pdf,我主要通过https://jalammar.github.io/illustrated-transformer/文章学习的。jalammar.github.io是一个十分值得一读的网站,他们通过可视化的方式深入浅出描述各种常见机器学习模型,从输入向量、模型内部详细步骤到模型输出通过动画或者图片形象展现出来。我这里挑主要内容分享一下Transformer模型,图片均来自该网站。
整体看
从整体上看,模型同样由encoder和decoder组成,只不过encoder和decoder分别由六层encoder和decoder叠加而成。六层只是Google实验时用了六层,并不是说大家在使用的时候必须是六层。
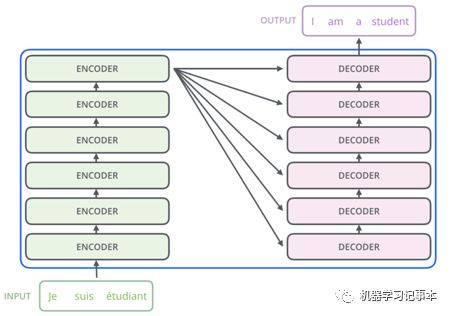
Encoder
每个encoder内部结构一样,对于第一个encoder,输入为整个模型的初始输入,如果是翻译系统,输入就是需要翻译的句子的各个单词向量表示。Encoder首先有一个Self-Attention层,核心思想是看看整个句子内各个单词之间的注意程度,和Attention机制中的注意程度是同一个概念,只不过这里考虑的是句子内部各个单词之间的注意程度,这样每个单词通过Self-Attention后得到一个新的向量,传入一个前馈神经网络,各个单词之间的这个前馈神经网络是独立的,其输出作为下一个encoder的输入。

再深入一点看,在前馈神经网络的前后还分别作了一次归一化处理。此外,在输出向量传给Self-Attention之前,还加了一个位置向量处理各个单词的位置。Self-Attention内部采用了Multi-Head Attention,简单点说就是采用多次Self-Attention再综合其结果。
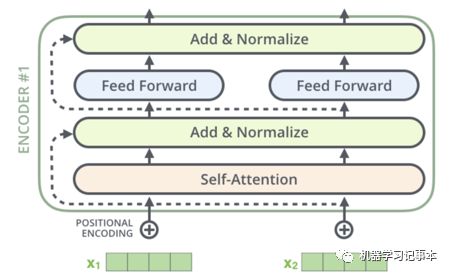
Decoder
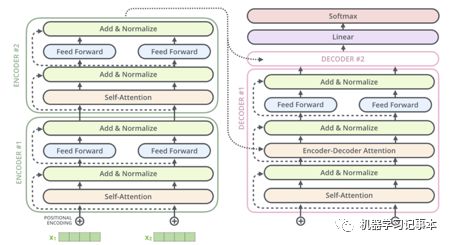
Decoder和encoder结构类似,只不过在Self-Attention后加了一层Encoder-Decoder Attention。Encoder最后一层的输出传给decoder中的Encoder-Decoder Attention,让decoder关注其应该注意的单词。如果是一个2层encoder和2层decoder的模型,整个模型看起来就是下面这个样。我第一次看见模型时也觉得很复杂,多理解几次就好了。
最终输出
如上图,在decoder后还有一层Linear和Softmax,这个是常见的处理方法,即通过一个线性变换和Softmax,让最终输出向量中每个值为一个概率值,其中最大值位置对应字典中的单词即为预测的单词。
以上即对ELMo、Attention和Transformer模型的描述,希望你对它们有了基本理解,在阅读相关文章时不会感到陌生,后续结合论文和开源项目也可快速使用起来。
