




摘要
大规模图上的子图匹配在社交网络挖掘,生物信息学,知识图谱等领域具有关键作用。近年来随着以GPU为代表的新硬件的发展,研究人员开始尝试在GPU上实现这一NP难的任务。GPU提供了大量的计算单元和高速的显存带宽,可以显著提升算法效率。然而,由于GPU特殊的线程架构和内存架构,充分利用GPU的硬件资源并非易事,这可能造成一个甚至几个数量级的性能差距。本文将对现有基于GPU的子图匹配算法提出的优化策略进行分类和对比。
引言
给定一个数据图和一个查询图,其中:
为顶点集合, 为边集合 为顶点标签映射函数
子图匹配问题定义为寻找所有满足以下条件的单射函数,满足:
.
子图匹配问题是经典的NP难问题,过往已经有诸多基于传统CPU的工作尝试提升其算法效率,然而这些方法都被CPU本身的计算能力所限制。近年来随着GPU的发展,研究人员开始探索在GPU上实现子图匹配任务。 然而,尽管GPU具有远超CPU的计算能力,其特殊的线程架构和内存架构使得简单地将算法移植到GPU上无法充分利用其计算资源。因此,本文先介绍GPU的线程和内存架构,分析在GPU上进行子图匹配的难点与挑战。
GPU的线程架构
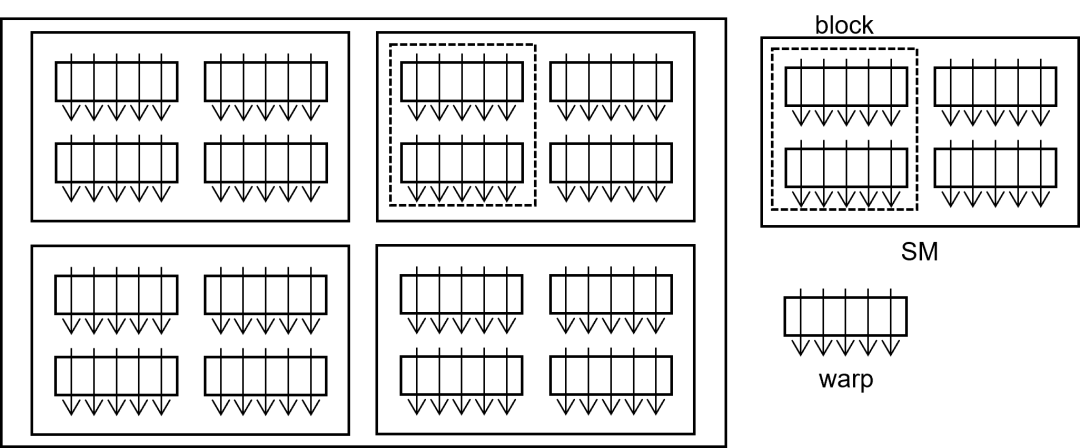
GPU的线程呈现分层的组织架构。如下图所示,GPU包含若干流多处理器(Streaming Multiprocessor, SM),每个SM中包含若干warp以供调度。 Warp是固定数量的线程组成的线程束(通常是32个线程)。SM按照warp为单位调度线程,warp内的线程执行相同的指令,即单指令多线程模型(Single Instruction Multiple Threads, SIMT)。 对于用户而言,线程被组织成若干个线程块(block)构成的线程网格(grid),线程块内的线程可以进行较便捷的数据交互和线程同步。 用户可以在发射GPU执行的核函数时指定一个线程块中的线程数目和总线程块数目。GPU根据每个线程块所需的寄存器和共享内存数目尽可能地将线程块分配给SM,一个线程块只能存在于一个SM中,而一个SM可以同时运行多个线程块。 SM可以调度其中所有线程块内所有的warp,当一个warp因为访存或者同步陷入停滞时,SM通过寻找可以执行的另一个warp继续执行。而当SM内没有可执行的warp时,其计算资源就被浪费。 与CPU的线程调度不同的是,GPU中具有大量的寄存器,寄存器由每个线程独享。因此在切换时,SM无需进行任何上下文切换,从而实现了高效线程调度。
GPU特殊的线程架构对于编程提出如下要求:
编程者需要尽可能避免warp内的线程因为条件或循环语句而进入不同分支,因为GPU不会同时执行不同的分支,而是分别顺序执行这些分支,阻滞不在当前分支的线程。 编程者需要尽量避免线程块及以上的线程同步,核函数的设计应使得每个warp具有相对独立的计算逻辑。 编程者需要合理地安排核函数的各种资源,使得一个SM能同时调度的线程块中能够有充足的warp以供调度来尽可能掩盖因为访存造成的停滞。同时要确保一个线程所需寄存器数量不超过限制,否则溢出的寄存器将使用缓慢的片下内存替代。
GPU的内存架构
GPU具有丰富多样的内存资源。总体来说可以分为高速的片上内存,和较低速的片下内存。
片上内存:类似于CPU中的片上内存结构,GPU中的内存包含寄存器和各级缓存结构。同时,GPU还具有特殊的共享内存(shared memory)可供用户指定存储频繁使用和线程块共享的信息。 寄存器:GPU每个SM中具有丰富的寄存器资源,但是这些寄存器被平均分配到每个线程中,用于存储线程内的变量。如果遇到寄存器溢出,编译器会将多余的寄存器用慢速的片下内存替代。 L1 Cache/shared memory:每一个SM具有一定数量(大约数百KB)的L1 Cache和shared memory,它们共享一片内存,延迟大概在数十个时钟周期。L1 cache由系统决定存储内容,而shared memory由编程者定义,在线程块内存共享。 shared memory中的访存使用多bank存储方式。总共有32个bank,按照4字节为单元顺序存储到每个bank中。当一个warp同时访问shared memory中相同bank的不同地址的内容,即地址差距为128的倍数时,会发生bank conflict,需要通过多次访存才能完成。 L2 Cache:所有SM共享L2 Cache,访存延迟大约在300个时钟周期左右。 片下内存:一般统称为显存,访存延迟大约在500个时钟周期左右,但是可以根据功能细分成global memory,local memory。constant memory等。 global memory:所有线程共享,可以从CPU端进行分配和初始化以将数据传递给核函数。global memory的每次访存按照128字节对齐的方式每次返回128字节的内容,称为合并访存(coalesced access)。编程者需要尽可能保证访问对齐的内容,从而避免带宽浪费。 local memory:用于存放溢出的寄存器和GPU上函数调用时暂存寄存器。 constant memory:用于存放在GPU端不会修改的内容,其中的内容在读取时会使用独立的只读缓存。
为了充分释放GPU的性能,编程者需要注意以下几点:
利用好shared memory,用于线程块内信息共享和手动缓存频繁使用的信息,减少访问显存的次数。 合理排布数据结构。尽可能保证访问global memory时以128字节对齐的方式访问相邻的内存。在访问shared memory时,要尽可能避免bank conflict。 
GPU上子图匹配的挑战
子图匹配具有复杂的逻辑和不均匀的数据分布。尽管传统CPU上已经发展了诸多优化方案,但是并非所有优化都能很好地贴合GPU的编程架构。例如,GPU上在核函数内不支持灵活的内存动态分配操作,所有内存应当预先在CPU端进行分配和初始化,因此基于运行时的动态剪枝等策略很难实现在GPU上。又例如,GPU中大量的线程使得线程间的同步和信息交互开销相对困难,可能造成线程块甚至整个线程网格的停滞。
传统CPU上的子图匹配大致包含过滤——匹配顺序选择——枚举三个部分。其中前两个部分复杂度为多项式量级,一般在预处理阶段完成,因此在GPU方案中可以较为简单地移植。而在枚举部分,GPU方案则进行比CPU更复杂的线程管理。其中的各种优化策略也因为GPU的内存和线程架构而无法直接使用CPU方案。
算法策略对比
本文将GPU上子图匹配按照搜索策略分为两类:BFS为基础按照层级顺序进行的搜索和DFS为基础按照子树顺序进行的搜索。搜索策略决定了算法需要解决的问题,并限制了优化策略。在总体搜索策略确定后,需要设计计算框架以充分利用GPU的硬件资源,避免内存溢出或者负载不均衡。在计算框架下,尽可能减少冗余计算和利用GPU提供的硬件支持可以有效地提高吞吐量。
搜索策略
子图匹配算法一般可以视作一棵搜索树。其中每个树节点表示一个子匹配。每次选取一个树节点所代表的子匹配,子图匹配算法需要选择一个尚未拓展的查询点,对当前子匹配拓展该查询点的所有可能的匹配作为当前树节点的子节点。具体而言,通过计算待匹配顶点的后向邻居的匹配点的邻域的交集,并进行去重操作即可获得所有可能的匹配方式。其中,后向邻居指的是当前待匹配查询点的已匹配邻居。
拓展搜索树的搜索策略决定了整个算法的计算框架。总体来说,我们可以将子图匹配算法按照搜索策略分成BFS和DFS两类。
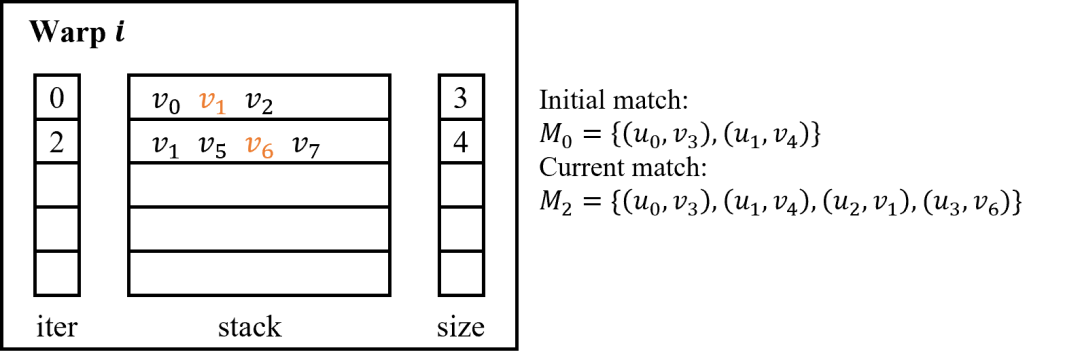
BFS策略:在基于GPU的BFS搜索中,每次发射一个核函数,将现有的子匹配拓展一个顶点[1,2,5,7]。在核函数中,每个warp每次接取一个子匹配,并搜索所有可能的拓展顶点,并生成新的子匹配。BFS搜索策略可以充分利用GPU的并行资源,其每一个线程的工作负载相对均衡。但是当查询图顶点数增多时,每一层子匹配数量指数增加。这就可能导致显存空间不足,匹配失败。此外,频繁地发射核函数,重新分配内存也会导致额外的开销。 DFS策略:在基于GPU的DFS搜索中,使用一个核函数完成整个搜索过程[4,6,9,10]。通过在global memory和shared memory中手动维护栈来实现递归搜索。如下图所示,在global memory中维护stack数组,其层数等于待匹配顶点数,其每层用于容纳当前搜索子树下对应层的不同匹配分支,每层的容量为数据图最大顶点度数。在shared memory中维护栈相关的元数据,包括一个iter数组,指向每层当前搜索分支,以及一个size数组,表示stack每层的匹配分支数。DFS算法中每一个warp每次接取一个初始匹配并按照DFS顺序进行搜索。在DFS算法中,内存开销是有限的,随着查询图顶点数和数据图最大顶点度数线性增长。然而,由于数据图密度分布不均匀,搜索子树的大小随着查询图顶点数量指数增加,这会导致严重的负载不均衡。此外,因为搜索栈在global memory中进行维护,访问和维护栈中元素也会导致额外的内存开销。
为了应对两种策略各自的不足,研究者尝试使用DFS-BFS的混合策略。
cuTS[3] 提出了在BFS搜索策略中引入DFS搜索的方案。它将所有初始子匹配按照chunk进行分组,每次选择一个chunk进行BFS搜索。这样可以缓解内存不足的问题。但是当查询图顶点进一步增加时,即便是一个chunk中拓展出的子匹配也会超过显存容量。
EGSM[8] 使用了先BFS,后DFS的搜索策略。它先尽可能地使用BFS策略拓展子匹配。当超过预先开辟的内存容量时,转而用DFS策略完成余下搜索工作。这种方案可以大大减少单个warp的搜索树粒度,从而减少负载不均衡问题,但是同样无法从根源上消除负载不均的问题。
总之,在BFS搜索中无法避免显存不足的问题,而DFS搜索必须面对负载不均的问题。因此,最近的工作采用了具有负载均衡策略的DFS搜索。
负载均衡策略
在基于DFS搜索算法中,可以通过将繁忙warp的任务动态卸载一部分给空闲warp从而实现负载均衡。这种策略可以确保所有warp不会进入长时间空闲,从而基本保证了负载的均衡。
然而,如何有效地在高并发环境中实现高效的负载均衡策略并非易事。
BEEP[9]和STMatch[6]在global memory中维护了一个空闲warp的Worker Queue,当繁忙warp发现Worker Queue中存在空闲warp时主动将一部分任务分配给该warp。该方案需要繁忙warp频繁地检查Worker Queue,从而产生了较大开销。
STMatch在线程块内还实现了更快捷的任务窃取策略,空闲warp可以直接从繁忙warp的栈中分割一部分任务。然而在GPU的高并发环境中,必须对栈进行加锁操作,从而增加了维护成本。
T-DFS[10]则提出了基于超时策略任务释放策略。每个warp通过GPU提供的clock64()函数记录当前搜索任务的运行时间。当运行时间超时时,主动分割一部分任务到Task Queue中,并重置运行时间。空闲的warp则等待Task Queue中的任务执行。直到所有warp进入空闲状态。通过使用合适的超时参数,可以有效控制负载均衡的开销和空闲warp的等待时间。
过滤策略
GPU中的过滤策略为每一个查询点生成一个较小的候选集,可以有效地对搜索树进行剪枝。 由于此部分策略一般在预处理阶段执行,GPU中基本沿用了CPU中基于Neighborhood的过滤策略。 为了在GPU上实现更快的过滤方案,部分工作设计了适合GPU访存模式的数据结构。例如,GSI[1]设计了按位存储的signature table,充分利用了合并访存的特性。EGSM[8]设计了cuckoo trie,支持对侯选边的批量插入,检查和删除。
匹配顺序选择策略
匹配顺序会影响搜索树的大小,良好的匹配顺序可以使得大部分无用的搜索分支较早被终止。 GPU上的匹配顺序一般使用启发式的静态匹配顺序。 例如,T-DFS[10]给度数和约束更多的查询点更高的优先级。而GSI[1]则选择候选集大小乘度数最小的点作为先匹配的点。 只有EGSM[8]使用了动态的匹配顺序。在用DFS进行搜索时,每次选择后向邻居最小邻域最小的顶点进行匹配。
重用策略
重用策略用于减少重复的拓展计算。由于子图匹配算法中集合求交运算占据了主要时间,而每一次集合求交运算都是若干数据图顶点的邻域进行求交。在整个搜索过程中,一些顶点的邻域频繁参与求交运算,研究者希望寻找重复的邻域求交运算,进行缓存并重复使用结果,减少计算冗余。
在CPU上的方案已经提出了相当多的重用策略。然而在GPU上不能很容易地移植这些策略。主要是因为(1)GPU上无法在核函数内动态分配内存,因此需要解决缓存结果存储位置的问题,以及(2)GPU上难以实现便捷高效的索引结构,因此需要解决缓存结果查询的问题。 因此,目前GPU上的重用策略要求在预处理阶段可以确定可重用部分,预先划分缓存空间并给出查询缓存结果的方式。这些重用策略基于对查询图进行分析,主要利用查询图顶点的对称性和独立性。
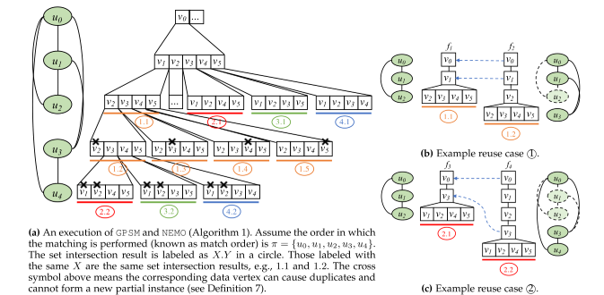
基于查询图顶点对称性的重用策略 Symmetry Breaking:该方案来源于CPU上的重用策略。对于自同构的查询图,该方案避免对自同构的匹配进行重复的计算。 基于后向邻居包含关系的重用:该方案来源于CPU上的重用策略。对于一个固定匹配顺序的查询图,如果后匹配的顶点的后向邻居包含先匹配顶点的后向邻居,则可以直接重用数据栈中对应行的内容作为中间结果。 基于约束包含关系的重用:RPS[7]提出了约束包含关系。对于前个查询顶点构成的导出子图,如果它子图同构于前查询顶点构成的子图,同时该同构在匹配顺序中保序。则对于第个顶点,其后向邻居可能的集合严格包含于第个顶点的对应后向邻居的可能集合(约束包含)。例如下图中和,之间就存在这种约束包含关系。在BFS搜索中,一定可以找到第层的对应结果进行重用。
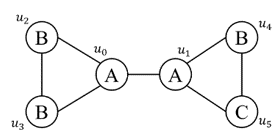
基于查询图顶点独立性的重用策略 STMatch[6]利用了在诸如下图所示的查询图中,的选择独立于的匹配选择。因此在DFS搜索时,会对相同的多次进行邻域求交。因此STMatch在预处理阶段检测这种独立性,并在栈中增加行存储,以进行重用。
多GPU系统上的计算
部分工作探索了在多GPU系统上进行子图匹配。 cuTS[3]采用了简单将不同chunk分配到不同GPU上,而将数据图复制到每个GPU上的策略。 PBE[2]利用Metis算法将数据图划分,使得跨分片的边密度尽量小。在每个GPU上分配一个数据图分片并搜索分片内的匹配,而在CPU上搜索跨分片的匹配。 VSGM[5]根据查询图,对每一个数据图顶点搜索其匹配可达的K-hop邻居作为一个数据图分片,所有的搜索任务可以在分片中完成。VSGM将分片分配到单个或者多个GPU上,并用GPU计算时间掩盖分片准备和数据传输时间。
总结
本文从不同策略角度对现有基于GPU的方案进行了深入的对比和总结。在每一类优化策略上对不同的技术方案进行了分析。本文旨在总结过往工作中的优点与不足,为后续工作提供研究方向的启示。
参考文献
[1] Li Zeng, Lei Zou, M. Tamer ¨Ozsu, Lin Hu, and FanZhang. Gsi: Gpu-friendly subgraph isomorphism. In2020 IEEE 36th International Conference on DataEngineering (ICDE), pages 1249–1260, 2020.
[2] Wentian Guo, Yuchen Li, Mo Sha, Bingsheng He, Xi-aokui Xiao, and Kian-Lee Tan. Gpu-accelerated sub-graph enumeration on partitioned graphs. In Proceed-ings of the 2020 ACM SIGMOD International Con-ference on Management of Data, SIGMOD ’20, page1067–1082, New York, NY, USA, 2020. Associationfor Computing Machinery.
[3] Lizhi Xiang, Arif Khan, Edoardo Serra, MahanteshHalappanavar, and Aravind Sukumaran-Rajam. cuts:scaling subgraph isomorphism on distributed multi-gpu systems using trie based data structure. In Pro-ceedings of the International Conference for High Per-formance Computing, Networking, Storage and Anal-ysis, SC ’21, New York, NY, USA, 2021. Associationfor Computing Machinery.
[4] Vibhor Dodeja, Mohammad Almasri, Rakesh Nagi,Jinjun Xiong, and Wen-mei Hwu. Parsec: Parallel subgraph enumeration in cuda. In 2022 IEEE Inter-national Parallel and Distributed Processing Sympo-sium (IPDPS), pages 168–178, 2022.
[5] Guanxian Jiang, Qihui Zhou, Tatiana Jin, Boyang Li,Yunjian Zhao, Yichao Li, and James Cheng. Vsgm:View-based gpu-accelerated subgraph matching on large graphs. In SC22: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–15, 2022.
[6] Yihua Wei and Peng Jiang. Stmatch: accelerating graph pattern matching on gpu with stack-based loop optimizations. In Proceedings of the International Conference on High Performance Computing, Net-working, Storage and Analysis, SC ’22. IEEE Press,2022.
[7] Wentian Guo, Yuchen Li, and Kian-Lee Tan. Exploiting reuse for gpu subgraph enumeration. IEEETransactions on Knowledge and Data Engineering,34(9):4231–4244, 2022.
[8] Xibo Sun and Qiong Luo. Efficient gpu-acceleratedsubgraph matching. Proc. ACM Manag. Data, 1(2),June 2023.
[9] Samiran Kawtikwar, Mohammad Almasri, Wen-MeiHwu, Rakesh Nagi, and Jinjun Xiong. Beep: Balanced efficient subgraph enumeration in parallel. In Proceedings of the 52nd International Conference onParallel Processing, ICPP ’23, page 142–152, New York, NY, USA, 2023. Association for Computing Machinery.
[10] T-DFS Lyuheng Yuan, Da Yan, Jiao Han, Akhlaque Ahmad,Yang Zhou, and Zhe Jiang. Faster depth-first sub-graph matching on gpus. In 2024 IEEE 40th International Conference on Data Engineering (ICDE),pages 3151–3163, 2024.


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore




