




1、引言
地理探测器主要用于探测空间分异性,以及揭示其背后驱动因子(王劲峰等,2017)[1]。地理探测器的功能主要包括分异及因子探测、交互作用探测、风险区探测、生态探测等4种探测器,其中最常使用的为分异及因子探测,即计算出q值与p值,以揭示地理要素的空间分异性,探究地理要素的影响因素。本文以R语言中用于地理探测器分析的GD包为例,展示如何使用GD包进行地理探测器分析过程,内容主要参考GD包中的manual[2]、Vignettes[3]及《地理探测器:原理与展望》一文,在code部分进行了一些优化与调整。
2、一个简单的示例
地理探测器目前有可在Windows系统运行的Excel版,并提供了一个简单的示例,本文首先以该示例文件中的数据为例,使用R语言中的GD包进行演示。由于地理探测器要求自变量x需为离散型变量,在该示例中,x已为离散型变量,因此可以直接用于地理探测器分析。
下载package与加载数据。test数据可后台回复20220109获取。
setwd("C:\\Users\\Acer\\Desktop")#设置工作路径
install.packages("GD") #安装包
library(GD) #加载包
test <- read.csv("test.csv") #读入数据
head(test) #查看数据
# incidence type region level
#1 5.94 7 5 5
#2 5.87 5 5 5
#3 5.92 5 5 5
#4 6.32 1 7 1复制
2.1 分异及因子探测。分异及因子探测主要用于探测Y的空间分异性;以及探测某因子X多大程度上解释了属性Y的空间分异,用q值度量,利用GD包中的gd() 函数。
test.fd <- gd(incidence ~ type + region + level, data = test) #构建模型,第一个变量为因变量,后面为自变量,data用于指定数据
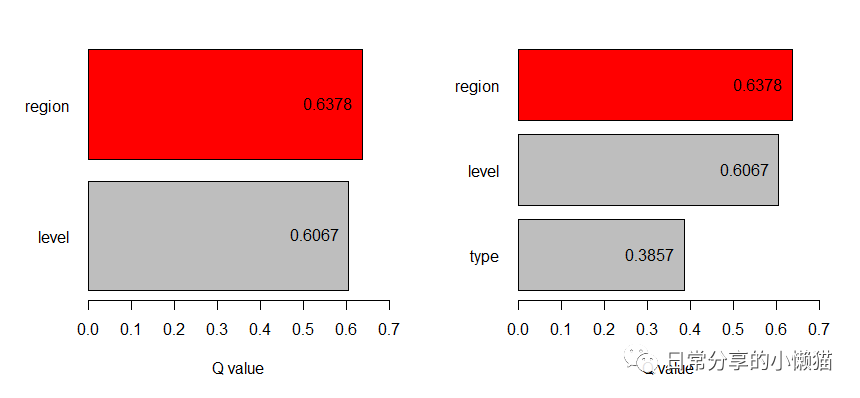
test.fd #查看结果,qv即为地理探测器的q统计量,用来度量自变量对因变量的解释度,sig为显著性水平
# variable qv sig
#1 type 0.3857168 0.372145486
#2 region 0.6377737 0.000128803
#3 level 0.6067087 0.043382244
plot(test.fd) #绘图
plot(test.fd, sig = FALSE) #sig为FALSE表示不显著的q值也进行展示复制
2.2 交互作用探测。交互作用探测主要用于识别不同风险因子X之间的交互作用,即评估因子X1和X2共同作用时是否会增加或减弱对因变量 Y 的解释力,或这些因子对Y的影响是相互独立的,利用GD包中的gdinteract() 函数。
test.gdinter <- gdinteract(incidence ~ type + region + level, data = test)
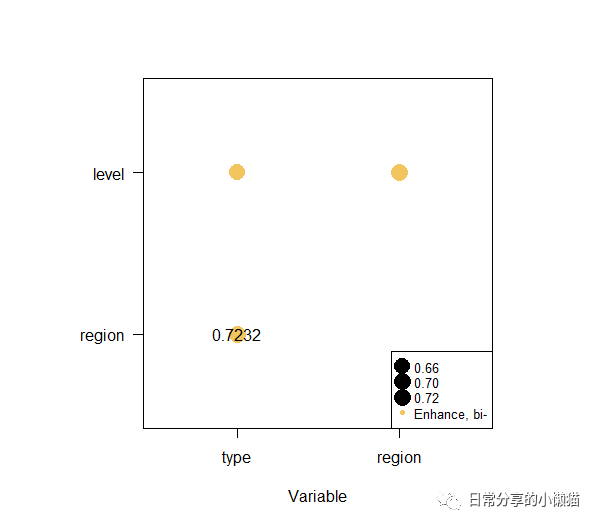
test.gdinter #查看结果
#Interaction detector:
# variable type region level
#1 type NA NA NA
#2 region 0.7232 NA NA
#3 level 0.6630 0.7103 NA
plot(test.gdinter) #绘图复制
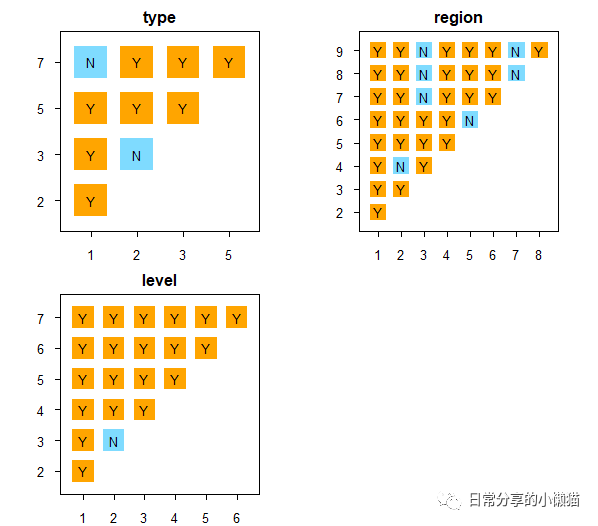
2.3 风险区探测。风险区探测主要用于判断两个子区域间的属性均值是否有显著的差别,利用GD包中的gdrisk() 函数。其中以sig=0.05为标准,小于0.05为显著,即Y,大于0.05为不显著,即N。
test.gdrisk <- gdrisk(incidence ~ type + region + level, data = test)
test.gdrisk #查看结果,
#type
# interval 1 2 3 5 7
#1 1 <NA> <NA> <NA> <NA> <NA>
#2 2 Y <NA> <NA> <NA> <NA>
#3 3 Y N <NA> <NA> <NA>
#4 5 Y Y Y <NA> <NA>
#5 7 N Y Y Y <NA>
#
#region
# interval 1 2 3 4 5 6 7 8 9
#1 1 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
#2 2 Y <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
#3 3 Y Y <NA> <NA> <NA> <NA> <NA> <NA> <NA>
#4 4 Y N Y <NA> <NA> <NA> <NA> <NA> <NA>
#5 5 Y Y Y Y <NA> <NA> <NA> <NA> <NA>
#6 6 Y Y Y Y N <NA> <NA> <NA> <NA>
#7 7 Y Y N Y Y Y <NA> <NA> <NA>
#8 8 Y Y N Y Y Y N <NA> <NA>
#9 9 Y Y N Y Y Y N Y <NA>
#
#level
# interval 1 2 3 4 5 6 7
#1 1 <NA> <NA> <NA> <NA> <NA> <NA> <NA>
#2 2 Y <NA> <NA> <NA> <NA> <NA> <NA>
#3 3 Y N <NA> <NA> <NA> <NA> <NA>
#4 4 Y Y Y <NA> <NA> <NA> <NA>
#5 5 Y Y Y Y <NA> <NA> <NA>
#6 6 Y Y Y Y Y <NA> <NA>
#7 7 Y Y Y Y Y Y <NA>
plot(test.gdrisk) #绘图复制
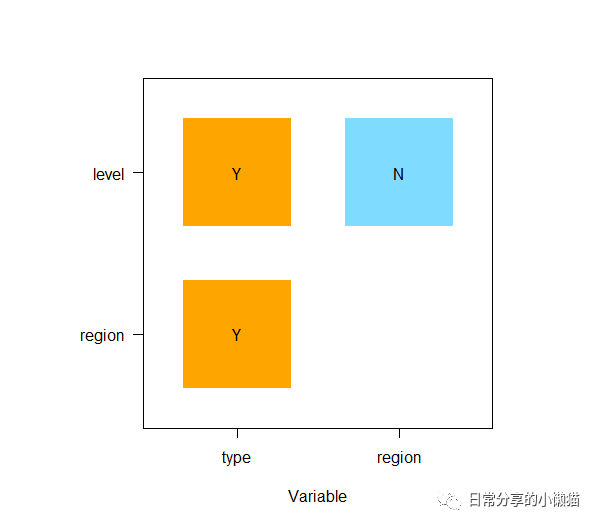
2.4 生态探测。生态探测主要用于比较两因子X1和X2对属性Y的空间分布的影响是否有显著的差异,利用GD包中的gdeco() 函数。
test.gdeco <- gdeco(incidence ~ type + region + level, data = test)
test.gdeco #查看结果
#Ecological detector:
# variable type region level
#1 type <NA> <NA> <NA>
#2 region Y <NA> <NA>
#3 level Y N <NA>
plot(test.gdeco) #绘图复制
2.5 综合。在GD包中提供了gdm() 函数,可用于一次输出上述4种探测的所有结果。
#一次输出所有结果
test.gdm <- gdm(incidence ~ type + region + level, data = test)
test.gdm #查看结果
plot(test.gdm) #绘图复制
3、一个综合的示例
上文中展示了一个可直接用于地理探测器分析的数据,但在实际研究中,数据往往不能直接用于地理探测器分析,由于地理探测器要求自变量x需为离散型变量,因此首先需要对连续型变量进行离散化处理。进行离散化的方法有常见的如使用ArcGIS中的自然断点法,SPSS中的k-means聚类等方法,而在GD包中提供了6种离散化方法,分别为equal(等距), natural(自然间断点分类-Jenks), quantile(分位数), geometric(几何间隔), sd(标准差), manual(手动间隔),每种分类方法的含义可参考ArcGIS Pro中的数据分类方法[4]介绍。同时,在GD包中提供了optidisc() 函数,可以通过算法自动计算出最优的方法及分类,对快速优化数据用于地理探测器分析具有方便、快捷的功能。
3.1 数据准备。利用GD包中自带的ndvi_40数据,该数据集包含NDVIchange,Climatezone、Mining、Tempchange、Precipitation、GDP、Popdensity等7个变量,后4个变量为连续型变量。在本文中,选择NDVIchange为因变量,选择Climatezone、Mining、Tempchange、Popdensity为自变量,进行地理探测器分析,其中Tempchange、Popdensity为连续型变量,需要首先进行离散化处理。
# 查看数据基本结构
data(ndvi_40)
head(ndvi_40)
# NDVIchange Climatezone Mining Tempchange Precipitation GDP Popdensity
#1 0.11599 Bwk low 0.25598 236.54 12.55 1.44957
#2 0.01783 Bwk low 0.27341 213.55 2.69 0.80124
#3 0.13817 Bsk low 0.30247 448.88 20.06 11.49432
#4 0.00439 Bwk low 0.38302 212.76 0.00 0.04620
#5 0.00316 Bwk low 0.35729 205.01 0.00 0.07482
#6 0.00838 Bwk low 0.33750 200.55 0.00 0.54941
> str(ndvi_40)
#'data.frame': 713 obs. of 7 variables:
# $ NDVIchange : num 0.11599 0.01783 0.13817 0.00439 0.00316 ...
# $ Climatezone : chr "Bwk" "Bwk" "Bsk" "Bwk" ...
# $ Mining : Factor w/ 5 levels "very low","low",..: 2 2 2 2 2 2 2 2 2 2 ...
# $ Tempchange : num 0.256 0.273 0.302 0.383 0.357 ...
# $ Precipitation: num 237 214 449 213 205 ...
# $ GDP : num 12.55 2.69 20.06 0 0 ...
# $ Popdensity : num 1.4496 0.8012 11.4943 0.0462 0.0748 ...
names(ndvi_40)
#[1] "NDVIchange" "Climatezone" "Mining" "Tempchange" "Precipitation" "GDP" "Popdensity"复制
3.2 确定数据离散化的最优方法与最优分类
discmethod <-c("equal","natural","quantile","geometric","sd") #选择离散化方法
discitv <-c(3:10)#定义间断点个数为3~10个
#optidisc(y~x, data,间断点方法, 间断点个数)
opt.Temp_Pop <-optidisc(NDVIchange ~ Tempchange + Popdensity, data = ndvi_40,discmethod, discitv)
opt.Temp_Pop #输出经过optidisc()函数计算后的最优方法与最优分类
#optimal discretization result of Tempchange
#method : quantile
#number of intervals: 10
#intervals:
# -0.39277 0.225738 0.471748 0.750186 1.041764 1.23631 1.363464 1.579234 1.855572 2.122304 3.22051
#numbers of data within intervals:
# 72 71 71 71 72 71 71 71 71 72
#optimal discretization result of Popdensity
#method : quantile
#number of intervals: 8
#intervals:
# 0 0.19673 0.73482 1.48121 3.17266 7.49744 18.85842 46.52966 970.8682
#numbers of data within intervals:
# 92 87 89 89 89 89 89 89
plot(opt.Temp_Pop) #对最优方法与最优分类进行可视化复制
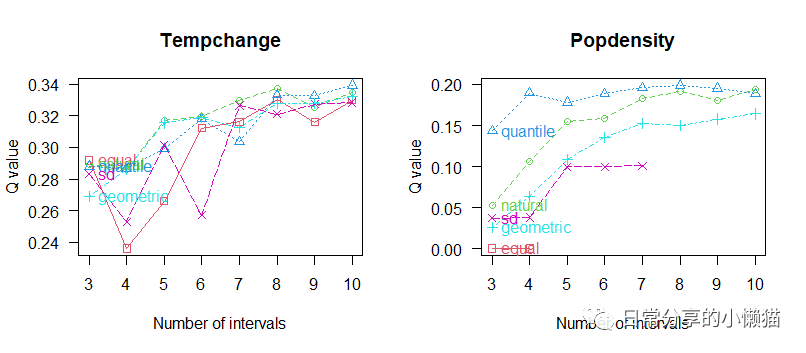
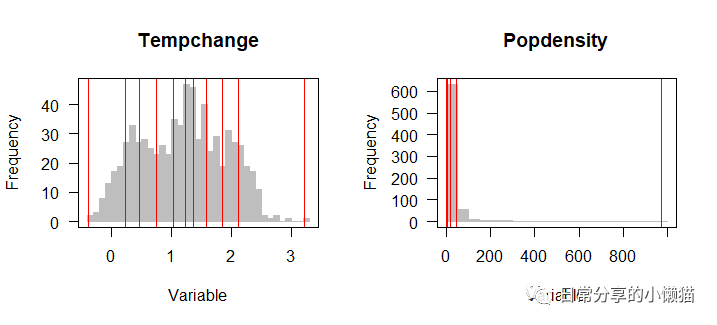
通过optidisc() 函数可以发现,对于Tempchange和Popdensity变量,都适合采用quantile离散化方法,其中Tempchange适合分为10类,Popdensity适合分为8类。
3.3 对数据进行离散化
odc.Tempchange <- disc(ndvi_40$Tempchange, 10, method = "quantile") #根据上述结果指定数据,分类数量以及分类方法
odc.Popdensity <- disc(ndvi_40$Popdensity, 8, method = "quantile")
odc.Tempchange #查看分类间隔
#Intervals:
# -0.39277 0.225738 0.471748 0.750186 1.041764 1.23631 1.363464 1.579234 1.855572 2.122304 3.22051
odc.Popdensity
#Intervals:
# 0 0.19673 0.73482 1.48121 3.17266 7.49744 18.85842 46.52966 970.8682
str(odc.Tempchange)#查看odc.Tempchange结构,itv为离散化的变量
#List of 2
# $ var: num [1:713] 0.256 0.273 0.302 0.383 0.357 ...
# $ itv: Named num [1:11] -0.393 0.226 0.472 0.75 1.042 ...
# ..- attr(*, "names")= chr [1:11] "0%" "10%" "20%" "30%" ...
# - attr(*, "class")= chr "disc"
str(odc.Popdensity)
#List of 2
# $ var: num [1:713] 1.4496 0.8012 11.4943 0.0462 0.0748 ...
# $ itv: Named num [1:9] 0 0.197 0.735 1.481 3.173 ...
# ..- attr(*, "names")= chr [1:9] "0%" "12.5%" "25%" "37.5%" ...
# - attr(*, "class")= chr "disc"复制
3.4 生成离散化后的新变量,需要用到cut() 函数,cut()函数用法可见第4部分
ndvi_40$dis.Tempchange <- cut(ndvi_40$Tempchange, breaks = odc.Tempchange$itv, include.lowest = TRUE)
ndvi_40$dis.Popdensity <- cut(ndvi_40$Popdensity, breaks = odc.Popdensity$itv, include.lowest = TRUE)
head(ndvi_40)
# NDVIchange Climatezone Mining Tempchange Precipitation GDP Popdensity dis.Tempchange dis.Popdensity
#1 0.11599 Bwk low 0.25598 236.54 12.55 1.44957 (0.226,0.472] (0.735,1.48]
#2 0.01783 Bwk low 0.27341 213.55 2.69 0.80124 (0.226,0.472] (0.735,1.48]
#3 0.13817 Bsk low 0.30247 448.88 20.06 11.49432 (0.226,0.472] (7.5,18.9]
#4 0.00439 Bwk low 0.38302 212.76 0.00 0.04620 (0.226,0.472] [0,0.197]
#5 0.00316 Bwk low 0.35729 205.01 0.00 0.07482 (0.226,0.472] [0,0.197]
#6 0.00838 Bwk low 0.33750 200.55 0.00 0.54941 (0.226,0.472] (0.197,0.735]复制
3.5 进行地理探测器分析
#分异及因子探测
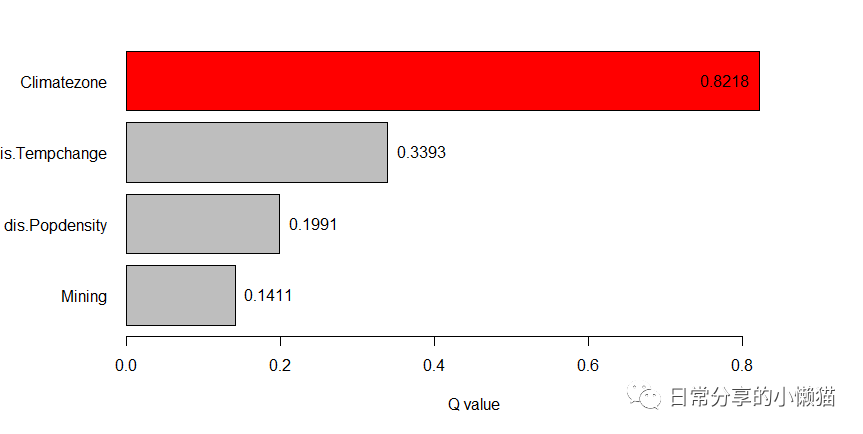
fd <- gd(NDVIchange ~ Climatezone + Mining + dis.Tempchange + dis.Popdensity, data = ndvi_40)
fd
# variable qv sig
#1 Climatezone 0.8218335 7.340526e-10
#2 Mining 0.1411154 6.734163e-10
#3 dis.Tempchange 0.3393024 4.352226e-10
#4 dis.Popdensity 0.1990773 6.640233e-11
plot(fd)复制
#交互作用探测
fd.gdinter <- gdinteract(NDVIchange ~ Climatezone + Mining + dis.Tempchange + dis.Popdensity, data = ndvi_40)
fd.gdinter
#Interaction detector:
# variable Climatezone Mining dis.Tempchange dis.Popdensity
#1 Climatezone NA NA NA NA
#2 Mining 0.8345 NA NA NA
#3 dis.Tempchange 0.8690 0.4242 NA NA
#4 dis.Popdensity 0.8597 0.3695 0.4747 NA
#风险区探测
fd.gdrisk <- gdrisk(NDVIchange ~ Climatezone + Mining + dis.Tempchange + dis.Popdensity, data = ndvi_40)
fd.gdrisk
#Climatezone
# interval Bsk Bwk Dwa Dwb Dwc
#1 Bsk <NA> <NA> <NA> <NA> <NA>
#2 Bwk Y <NA> <NA> <NA> <NA>
#3 Dwa Y Y <NA> <NA> <NA>
#4 Dwb Y Y N <NA> <NA>
#5 Dwc Y Y Y Y <NA>
#生态探测
fd.gdeco <- gdeco(NDVIchange ~ Climatezone + Mining + dis.Tempchange + dis.Popdensity, data = ndvi_40)
fd.gdeco
#Ecological detector:
# variable Climatezone Mining dis.Tempchange dis.Popdensity
#1 Climatezone <NA> <NA> <NA> <NA>
#2 Mining Y <NA> <NA> <NA>
#3 dis.Tempchange Y Y <NA> <NA>
#4 dis.Popdensity Y Y Y <NA>
#综合。该过程可能需要等待几分钟
discmethod <-c("equal","natural","quantile","geometric","sd")
discitv <-c(3:10)
fd.gdm <- gdm(NDVIchange ~ Climatezone + Mining + Tempchange + Popdensity, data = ndvi_40,discmethod = discmethod, discitv = discitv)
fd.gdm复制
4、cut()函数
在对数据离散化操作的过程中使用了一个比较常用的cut()函数,cut()函数常用于将一个连续变量转换为分。函数基本形式如下:
cut(x, breaks, labels = NULL,
include.lowest = FALSE, right = TRUE, dig.lab = 3,
ordered_result = FALSE, ...)复制
其中,x为一个连续型数值向量,breaks为间断点,labels为分类标签,include.lowest表示是否包含最小值,right = TRUE表示生成的区间为左开右闭。此外, 在分类中常用的参数表示还有正无穷(Inf)与负无穷(-Inf),由于cut()函数生成的默认区间为左开右闭,不包含最小值,因此如果需要将最小值纳入,则需要设定参数include.lowest = TRUE;如果想生成左闭右开的区间,则可以设定参数right = FALSE。
5、其他
本文以R语言中GD包为例,展示了地理探测器的分析过程,相较于可在Windows系统运行的Excel版地理探测器程序,在R语言中利用GD包以及相关数据操作函数的能够快速完成数据离散化操作、模型建立以及相关图形绘制等一系列流程。后续也将继续分享R语言中用于地理空间分析的其他方法,如有帮助多多点赞哦。
如有帮助请多多点赞哦!
参考资料
王劲峰,徐成东: 地理探测器:原理与展望[J].地理学报,2017,72(01):116-134.
[2]GD: https://cran.r-project.org/web/packages/GD/GD.pdf
[3]GD.Vignettes: https://cran.r-project.org/web/packages/GD/vignettes/GD.html
[4]数据分类方法: https://pro.arcgis.com/zh-cn/pro-app/latest/help/mapping/layer-properties/data-classification-methods.htm
评论

 0 点赞 0 点赞 0 点赞 0 点赞 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞 0 点赞 0 点赞 0 点赞