




本文主要介绍在使用pheatmap包绘制热图的过程中,如何添加自定义聚类标签。如以2001-2020年31个省份的人均GDP数据为例,进行聚类并添加不同省份对应的地区标签,如下图所示。数据来自国家统计局[1]。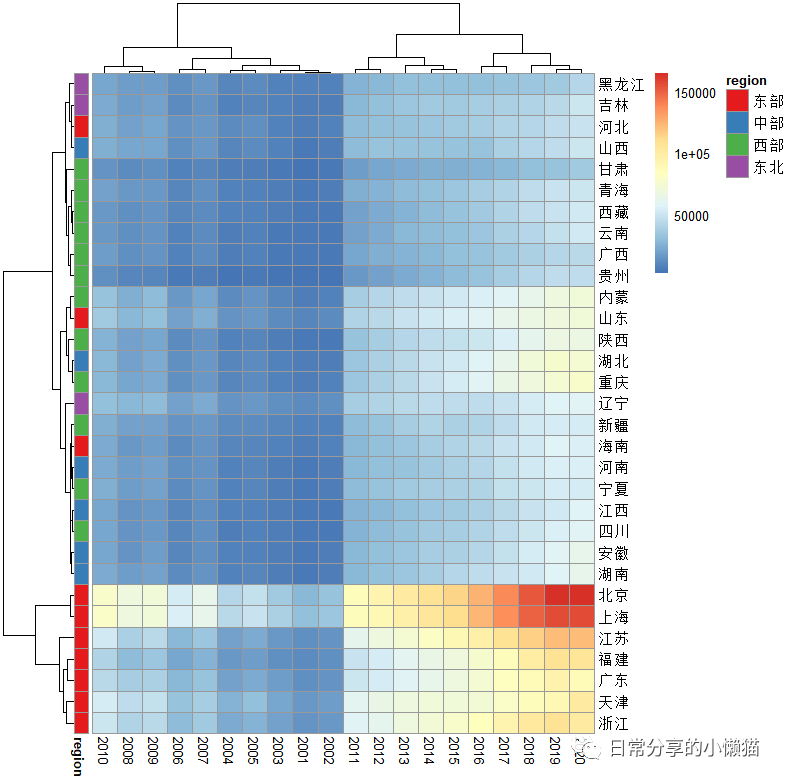
1、数据准备
library(tidyverse)
library(pheatmap)
dta <- readxl::read_xlsx("GDPdf.xlsx")
head(dta)
# # A tibble: 6 x 4
# province region year PerGDP
# <chr> <chr> <dbl> <dbl>
# 1 北京 东部地区 2020 164889
# 2 天津 东部地区 2020 101614
# 3 河北 东部地区 2020 48564
# 4 山西 中部地区 2020 50528
# 5 内蒙 西部地区 2020 72062
# 6 辽宁 东北地区 2020 58872
str(dta)
# tibble [620 x 4] (S3: tbl_df/tbl/data.frame)
# $ province: chr [1:620] "北京" "天津" "河北" "山西" ...
# $ region : chr [1:620] "东部地区" "东部地区" "东部地区" "中部地区" ...
# $ year : num [1:620] 2020 2020 2020 2020 2020 2020 2020 2020 2020 2020 ...
# $ PerGDP : num [1:620] 164889 101614 48564 50528 72062 ...
dim(dta)
# [1] 620 4
# 转换为矩阵数据
heatmap_dta <- dta %>% reshape2::dcast(province ~ year, value.var = "PerGDP") %>%
arrange(province) %>% column_to_rownames(var = "province") %>% as.matrix()
head(heatmap_dta)
# 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020
# 安徽 5732 6238 7001 8279 9193 10630 12989 15535 17715 21923 27314 30683 34256 37184 38983 42641 47671 54078 58072 63426
# 北京 28097 32231 36583 42402 47182 53438 63629 68541 71059 78307 86365 93078 101023 107472 114662 124516 137596 153095 164563 164889
# 福建 11883 12910 14330 16248 18107 20915 25915 30153 33999 40773 48341 54073 59835 65810 70162 76778 86943 98542 106966 105818
# 甘肃 4467 4875 5525 6512 7332 8653 10501 12048 12802 15421 18801 20978 23313 25202 25264 26520 28026 30797 32995 35995
# 广东 13952 15478 17950 20647 23997 27861 33236 37543 39418 44669 50676 54038 58860 63809 69283 75213 82686 88781 94448 88210
# 广西 5058 5559 6120 7182 8069 9421 11542 13471 14708 18070 22258 24238 26483 28687 30990 33458 36595 40012 42964 44309
str(heatmap_dta)
# num [1:31, 1:20] 5732 28097 11883 4467 13952 ...
# - attr(*, "dimnames")=List of 2
# ..$ : chr [1:31] "安徽" "北京" "福建" "甘肃" ...
# ..$ : chr [1:20] "2001" "2002" "2003" "2004" ...
dim(heatmap_dta)
# [1] 31 20复制
2、热图绘制
pheatmap(heatmap_dta)复制
3、添加聚类标签
# 设置省份所属地区
region_class <- dta %>% filter(year == 2020) %>% select(province, region) %>% arrange(province) %>% column_to_rownames(var = "province")
region_class
# region
# 安徽 中部地区
# 北京 东部地区
# 福建 东部地区
# 甘肃 西部地区
# 广东 东部地区
# 广西 西部地区
# 贵州 西部地区
# 海南 东部地区
# 设置每个地区的颜色类别
ann_colors = list(region = c(东部地区 = "#E41A1C", 中部地区 = "#377EB8", 西部地区 = "#4DAF4A", 东北地区 = "#984EA3"))
ann_colors
# $region
# 东部地区 中部地区 西部地区 东北地区
# "#E41A1C" "#377EB8" "#4DAF4A" "#984EA3"复制
4、含有自定义聚类标签的热图
pheatmap(heatmap_dta, annotation_row = region, annotation_colors = ann_colors)复制
可以发现,省份的聚类结果与我国四大地区划分具有一定的重合性,区域经济的空间差异较为明显。
5、tips
在添加自定义标签的过程,务必注意聚类数据库的行名必须与矩阵的行名保持一致。
其他
更多内容可关注微信公众号【日常分享的小懒猫】。
如有帮助请多多点赞哦!
参考资料
国家统计局: https://data.stats.gov.cn/index.htm
文章转载自日常分享的小懒猫,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
跟着论文学习数据库7:向量数据库
SQL和数据库技术
29次阅读
2025-04-01 12:27:00
IBM Db2 Warehouse云原生存储架构最新进展
数据库应用创新实验室
21次阅读
2025-04-15 09:56:59
深度好文:三大主流数据湖格式Hudi、Iceberg、Delta Lake的数据聚类技术对比详解
大数据从业者
16次阅读
2025-04-01 12:26:23
Vastbase向量版核心技术,帮助AI模型高效运行、性能飞跃
海量数据库
15次阅读
2025-04-03 09:56:06
论文导读 | 向量数据库中的关键技术及代表性工作简介
图谱学苑
10次阅读
2025-04-14 09:40:30
