




在数据分析学习的过程中,有时候需要用到面板数据,但收集面板数据又相对费时,因此本文主要介绍如何利用R语言生成一个随机的面板模拟数据,以方便必要时的数据分析与图形绘制。如下图所示: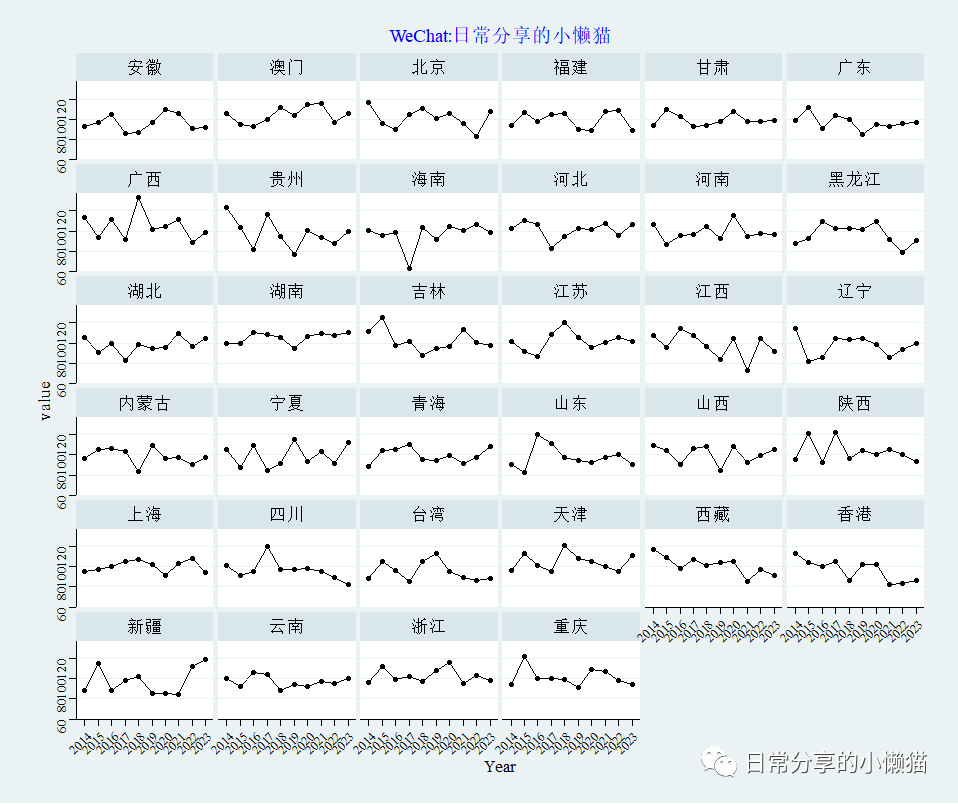
1、面板模拟数据生成
生成中国34个省份(自治区、直辖市、特别行政区)的2013—2023年的面板模拟数据。主要包括4个要素,id、province、year、value。
library(dplyr)
library(ggthemes)
library(ggplot2)
# id, province, year
province_name <- c("河北", "山西", "黑龙江", "吉林", "辽宁", "江苏", "浙江",
"安徽", "福建", "江西", "山东", "河南", "湖北", "湖南", "广东",
"海南","四川", "贵州", "云南", "陕西", "甘肃", "青海", "台湾",
"内蒙古", "广西", "西藏", "宁夏", "新疆", "北京", "天津", "上海",
"重庆", "香港", "澳门" )
province_name
panel_dta <- data.frame(
id = 1:34,
province = province_name,
year = rep(c(2014:2023), each = 34)) %>% arrange(id, year) %>%
mutate(value = rnorm( n = 340, mean = 100, sd = 10))
head(panel_dta)
# id province year value
# 1 1 河北 2014 102.92901
# 2 1 河北 2015 110.45113
# 3 1 河北 2016 106.42231
# 4 1 河北 2017 83.17789
# 5 1 河北 2018 94.24234
# 6 1 河北 2019 102.25605复制
2、面板数据绘图
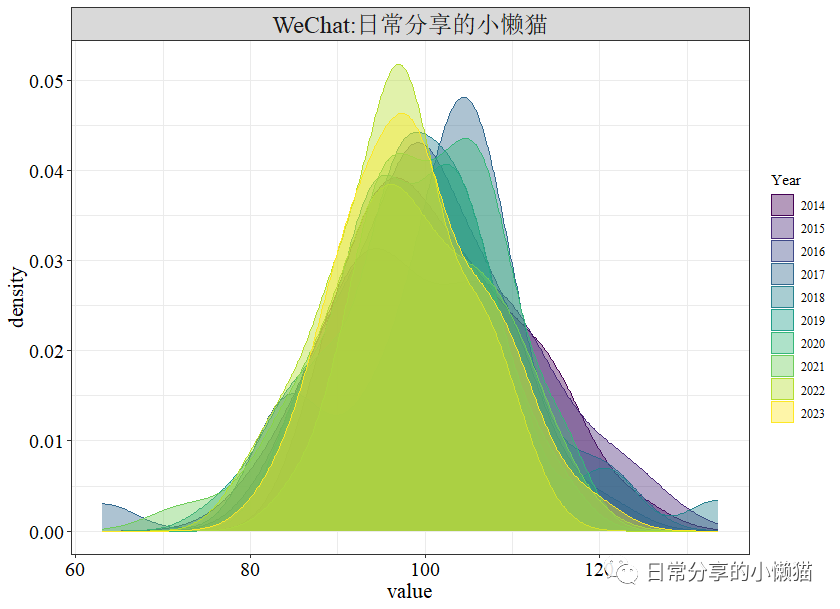
2.1 绘制密度图
绘制变量value的密度图
ggplot(panel_dta, aes( x = value, color = factor(year), fill = factor(year), group = year)) +
geom_density(alpha = 0.4) +
theme_bw() +
scale_fill_viridis_d() +
scale_color_viridis_d() +
labs(color = "Year", fill = "Year") +
theme(axis.text = element_text(size = 15, colour = "black"),
axis.title = element_text(size = 16))复制
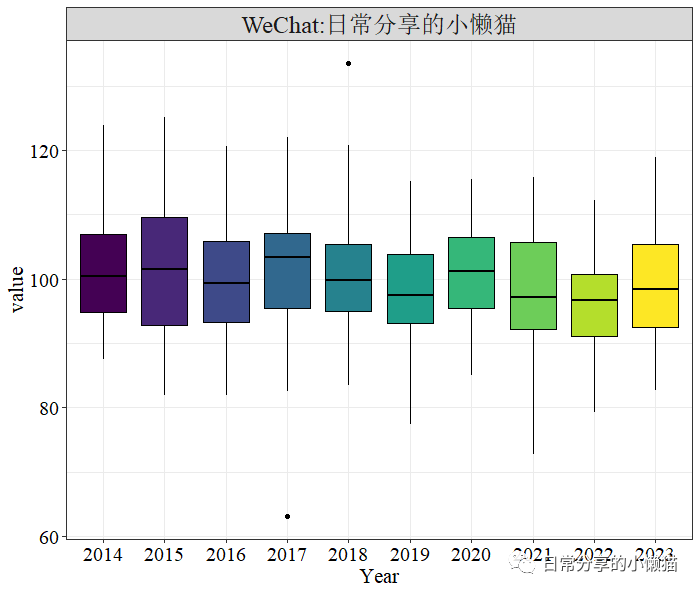
2.2 绘制箱线图
绘制变量value的箱线图
ggplot(panel_dta, aes( x = factor(year), y = value, fill = factor(year))) +
geom_boxplot(color = "black", show.legend = FALSE) +
theme_bw() +
scale_fill_viridis_d() +
scale_color_viridis_d() +
labs( x = "Year") +
theme(axis.text = element_text(size = 15, colour = "black"),
axis.title = element_text(size = 16))复制
2.3 绘制折线图
绘制面板折线图
ggplot(panel_dta, aes( x = factor(year), y = value, fill = factor(year) , group = 1 )) +
geom_line( show.legend = FALSE) +
geom_point( show.legend = FALSE) +
theme_stata() +
scale_fill_viridis_d() +
facet_wrap(~province ) +
scale_color_viridis_d() +
labs( x = "Year") +
theme(axis.text = element_text(size = 10, colour = "black"),
axis.text.x = element_text(angle = 45, hjust = 1),
axis.title = element_text(size = 13))复制
3、面板数据计算
计算value变量在不同年份的变异系数
panel_dta %>% group_by(year) %>% summarise(cv = sd(value)/mean(value))
# year cv
# <int> <dbl>
# 1 2014 0.0922
# 2 2015 0.110
# 3 2016 0.0878
# 4 2017 0.117
# 5 2018 0.104
# 6 2019 0.0900
# 7 2020 0.0750
# 8 2021 0.0994
# 9 2022 0.0814
# 10 2023 0.0831复制
4、其他
更多内容可关注微信公众号【日常分享的小懒猫】。
如有帮助请多多点赞哦!
文章转载自日常分享的小懒猫,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
484次阅读
2025-04-14 09:40:20
最近我为什么不写评论国产数据库的文章了
白鳝的洞穴
434次阅读
2025-04-07 09:44:54
优炫数据库成功入围新疆维吾尔自治区行政事业单位数据库2025年框架协议采购!
优炫软件
344次阅读
2025-04-18 10:01:22
国产数据库时代,一些20年前的数据库设计小技巧又可以拿出来用了
白鳝的洞穴
255次阅读
2025-04-10 11:52:51
关于征集数据库标准体系更新意见和数据库标准化需求的通知
数据库标准工作组
229次阅读
2025-04-11 11:30:08
TDengine 3.3.6.0 发布:TDgpt + 虚拟表 + JDBC 加速 8 大升级亮点
TDengine
198次阅读
2025-04-09 11:01:22
Apache Doris 2025 Roadmap:构建 GenAI 时代实时高效统一的数据底座
SelectDB
185次阅读
2025-04-03 17:41:08
优炫数据库成功应用于晋江市发展和改革局!
优炫软件
182次阅读
2025-04-25 10:10:31
GoldenDB助力江苏省住房公积金国产数据库应用推广暨数字化发展交流会成功举办
GoldenDB分布式数据库
175次阅读
2025-04-07 09:44:49
全国首部图数据库国家标准发布!达梦数据深度参与!
达梦数据
166次阅读
2025-04-02 09:34:13
