




洛伦兹曲线可用于直观表示地理要素的分布集中状况,是地理学研究中一个常见方法。本文主要介绍如何利用R语言绘制洛伦兹曲线。
1、数据准备
本文主要参考冯亚芬等(2017)
在地理科学发表的《广东省传统村落空间分布特征及影响因素研究》 一文。演示数据来自文中表1数据。数据也可以在后台回复【20220527】获取。具体如下: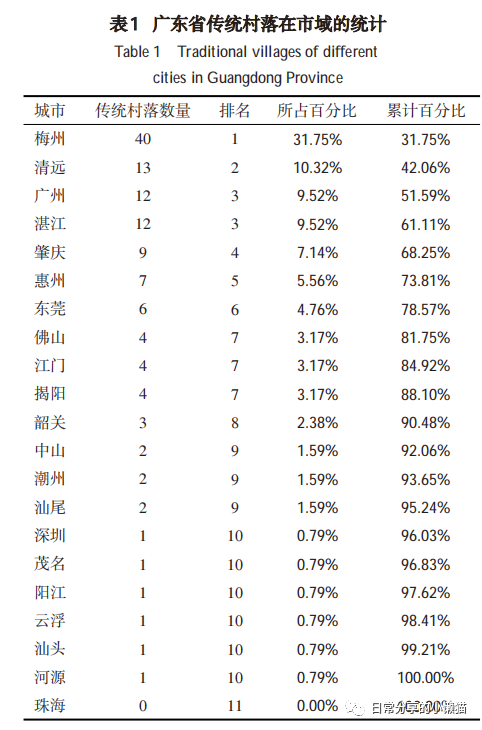
2、数据处理
2.1 数据导入与加载package
setwd("C:\\Users\\Acer\\Desktop\\R学习\\常用数据")
library(tidyverse)
library(reshape2)
data <- readxl::read_xlsx("不均衡指数.xlsx")
head(data)
# A tibble: 6 x 2
# region value
# <chr> <dbl>
#1 梅州 40
#2 清远 13
#3 广州 12
#4 湛江 12
#5 肇庆 9
#6 惠州 7复制
2.2 计算实际累计分布与均匀累计分布
my_data <- data %>%
arrange(-value) %>% #排序
mutate(value_sum = value/sum(value)*100, #实际占比
value_cum = cumsum(value_sum), #实际累计占比
mean_value = mean(value)/sum(value)*100, #均匀分布
mean_cum = cumsum(mean_value)) #均匀分布累计占比
my_data
# A tibble: 21 x 6
# region value value_sum value_cum mean_value mean_cum
# <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
# 1 梅州 40 31.7 31.7 4.76 4.76
# 2 清远 13 10.3 42.1 4.76 9.52
# 3 广州 12 9.52 51.6 4.76 14.3
# 4 湛江 12 9.52 61.1 4.76 19.0
# 5 肇庆 9 7.14 68.3 4.76 23.8
# 6 惠州 7 5.56 73.8 4.76 28.6
# 7 东莞 6 4.76 78.6 4.76 33.3
# 8 佛山 4 3.17 81.7 4.76 38.1
# 9 江门 4 3.17 84.9 4.76 42.9
#10 揭阳 4 3.17 88.1 4.76 47.6
# ... with 11 more rows复制
2.3 将宽数据转换为长数据,修改因子标签
#将宽数据转换为长数据
my_data2 <- my_data %>% dplyr::select(region,value_cum,mean_cum) %>%
reshape2::melt(id.vars = "region", value.name = "prop",variable.name = "type")
#修改因子标签
my_data2$type <- factor(my_data2$type, levels = c("value_cum", "mean_cum"), labels = c("实际分布", "均匀分布"))复制
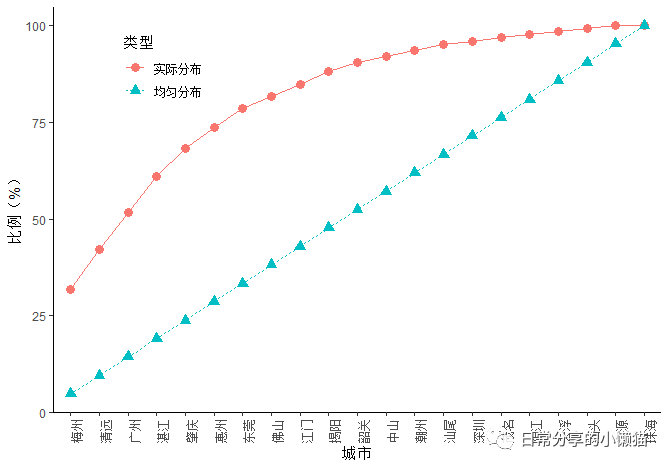
3、绘图
ggplot(my_data2, aes(reorder(region, prop) , prop, color = type,shape = type, linetype = type, group = type)) +
geom_line() +
geom_point(size = 3) +
theme_classic() +
labs(x = "城市", y = "比例(%)", fill = "类型",color = "类型",shape = "类型", linetype = "类型") +
theme(legend.position = c(0.2, 0.85),
axis.text.x = element_text(angle = 90))复制
4、其他
关于洛伦兹曲线的绘制的其他方法可参考R语言与Stata绘制洛伦兹曲线(Lorenz curve)。 关于地理集中指数计算可参考R数据分析|地理集中指数。 关于空间基尼系数计算可参考R数据分析|空间基尼系数。 关于不均衡指数计算可参考R数据分析|不均衡指数。 更多内容可阅读公众号其他文章。
如有帮助请多多点赞哦!
文章转载自日常分享的小懒猫,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
金仓数据库26套!宁波市司法局信息系统适配改造(一期)采购项目
天下观查
334次阅读
2025-03-21 10:33:59
国产化+性能王炸!这套国产方案让 3.5T 数据 5 小时“无感搬家”
YMatrix
309次阅读
2025-03-13 09:51:26
大连农商40万,采购Greenplum数据库原厂订阅服务
天下观查
286次阅读
2025-03-13 09:52:29
国产数据库高光时刻!天翼云TeleDB荣登TPC-DS全球测评总榜第二
天翼云开发者社区
191次阅读
2025-03-13 17:24:48
为什么总是很难客观评价某个国产数据库产品
白鳝的洞穴
185次阅读
2025-03-19 11:21:09
史诗级革新 | Apache Flink 2.0 正式发布
严少安
168次阅读
2025-03-25 00:55:05
晨章数据三款分布式数据库产品全面开源,以开放向AI时代进发
晨章数据
153次阅读
2025-03-10 17:10:07
天翼云:Apache Doris + Iceberg 超大规模湖仓一体实践
SelectDB
146次阅读
2025-03-18 15:02:51
Apache Doris 2025 Roadmap:构建 GenAI 时代实时高效统一的数据底座
SelectDB
135次阅读
2025-04-03 17:41:08
最近我为什么不写评论国产数据库的文章了
白鳝的洞穴
130次阅读
2025-04-07 09:44:54
